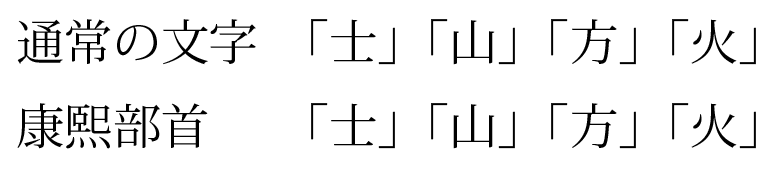VR/ARでの読書について思うこと
2020/11/13先日、メディアドゥからVR/AR用の電子書籍ビューア開発開始というニュースリリースの発表がありました。また、Facebookはスタンドアロンで動作する普及版VRビューア、Oculus Questの後継機に当たるOculus Quest 2を販売開始し、これがいよいよ家電量販店で売られるなどという話も出ています。そろそろ本格的にVR/AR普及が見えてきた感がありますので、ちょっとVR/ARでの読書について期待するところを書いてみたいと思います。
VRによるデバイス画面サイズの制約からの解放
今、私たちは電子書籍を例えばスマートフォンで、あるいは専用機やタブレットで、もしくはPCの画面で読んでいます。これらの「画面」は、いずれも物理的な実サイズを持っていて、必然的に表示できる文字やイラストの大きさにはデバイスの物理サイズによる制限がかかります。これを緩和するために行っている作業が「テキストリフロー化」で、そうすることで紙の本からの電子化であってもスマートフォンの小さな画面でもとりあえず読めるようにはなります。
リフロー型電子書籍では紙の版面情報の再現は難しい
さらに、テキストリフロー化はその過程で多くの情報を強制的に削ぎ落とす行為です。例えば実用書などでは見開きの片方のページに大きく図を表示し、もう片方のページに解説文を載せるといったレイアウトのものがありますが、これはテキストリフローでは再現できません。このため、図版の挿入位置を工夫し、テキストの文言を調整するといった作業を行いますが、当然限界はあります。
VRによってデバイスサイズによる縛りがなくなり、任意のサイズの仮想的な画面を展開できるようになればそのあたりの悩みは一気に解消されるはずです。なにしろ仮想画面なので、例えば「新聞の見開きサイズの画面を展開する」といったことも可能になるわけです。これはとてつもなく大きな進化です。
仮想画面はいくつ出してもよい
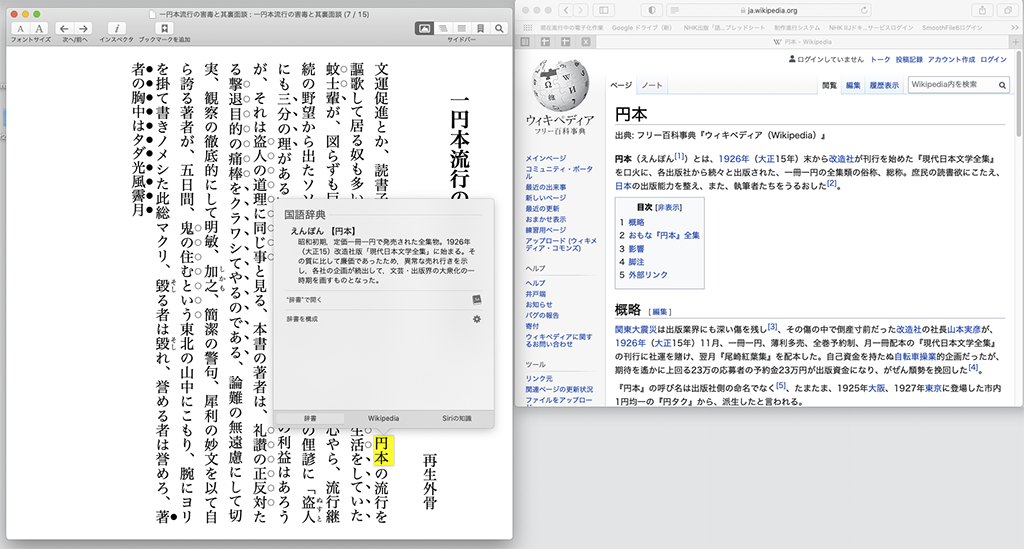
複数の「画面」を並べて行うPCでの読書
まず、読書対象の本そのものの版面。用語がわからなければそれを調べるために辞書を引くこともあるでしょうからそれも「画面」の一つ。ネットを使って検索して調べることもあるでしょうし、文章中で他の本を引用している箇所があれば、その本を持ってきて該当箇所を調べるようなこともやるでしょう。内容を書き留めるための手元のノートも「画面」と見ることができそうです。
さらには読書対象の本の中に注が設定されていれば、それと本文を相互参照しながら読むこともしますので、これもそれぞれ別の「画面」と見ることができるでしょう。つまり「読書」というのはそういう多くの「画面」を随時参照しながら行う行為なのだと思います。
そう考えると、今電子版で売れているのが圧倒的にコミックスやライトノベルのような軽いエンタメで、カタい本が売れにくい状況になっているのも理解できます。コミックスやライトノベルを読むなら「画面」はひとつで済みますが、カタい本を読むにはひとつでは足りないのです。VR技術によって、物理的に多くの面積を専有することなしに多数の「画面」を並べて本を読めるようになれば、それはかなり幸せな読書体験になるのではないかなと思います。
必ずしも全てが仮想画面でなくてもよい
さて、そうは言っても「やはり紙の本がいい」という方はたくさんいるのではないかと思います。でも例えば、紙の本を読みながら辞書や参考文献などを仮想画面として適宜呼び出せるとしたらどうでしょうか。単に別画面を見せるだけなら「スマホを横に置いておけばいいじゃん」という意見が出そうですが、おそらくGoogleやAppleあたりはそれだけでは済ませない世界を構想しているように思えます。紙の本を読みながら、わからない用語があったときにタッチペン的なものでなぞれば視界内に辞書の用語解説ページが仮想画面としてポップアップしてきて参照できる、そんな世界が来るように思うのです。
そういった現実世界のものに電子情報をオーバーライドして見せる技術は「AR(Augmented Reality/拡張現実)」と言い、こちらは現在GoogleやAppleが熱心に研究を進めている分野です。今はまだ視界全てを置き換えるVRとは別物として開発されていますが、VR機器の前面のカメラで周囲の映像を取り込んで内部ディスプレイに投影すればAR的な表示ができますので、本質的に地続きの話です。なのでMicrosoftなどはMR(Mixed Reality)という用語を使っていたりもします。

Google翻訳ではスマホをかざすだけで翻訳文が表示される
もちろん超えなければならない技術的な壁はまだいくつもあるでしょうが、もう想像できないほど先の話ではないように思います。5年後、10年後にはARメガネをかけながら読書している人はちらほら見かけるようになるのではないでしょうか。期待をこめてそういう世界の到来を待ちたいと思っています。
(2020.11.13)