WindowsでXojoからPerlを呼び出して使う
2017/09/25Xojoはクロスプラットフォーム開発環境なわけですが、Xojo単体内部でコードが完結してるならともかく、外部のPerlやらなんやらに処理を投げようとするといろいろプラットフォーム環境に依存して面倒なわけです。Macは根っこがBSDUnixなのでデフォルトでいろいろ入ってて面倒がないんですけどね。ということでどうにかこうにかWindowsでXojoからPerlに処理を投げることに成功したのでメモです。@kmutoさん、いろいろと助言ありがとうございました。助かりました。
StrawberryPerlをインストールして環境を構築
まず、無料のPerl環境、StrawberryPerlをインストールして環境を構築しました。当初Windows10のBash on Ubuntu on Windowsに処理を投げようとしたり、ActivePerl使おうとしたりで四苦八苦しましたが、Bash on Ubuntu on WindowsだとXojo内からシェル経由でコマンド投げようとするといろいろ支障が出てきて動かなかったり(一応このあたりに知見はあるようなんですが手に負えず)、ActivePerlはXMLパーサーモジュールのインストールこれどうすりゃいいのよだったりして結局StrawberryPerlに落ち着きました。これ素晴らしいです。インストーラ普通にあるしCPAN普通に使えるし。セットアップはこのあたりを参考に。
実行ファイルと同じフォルダにPerlのファイルをコピーする指定
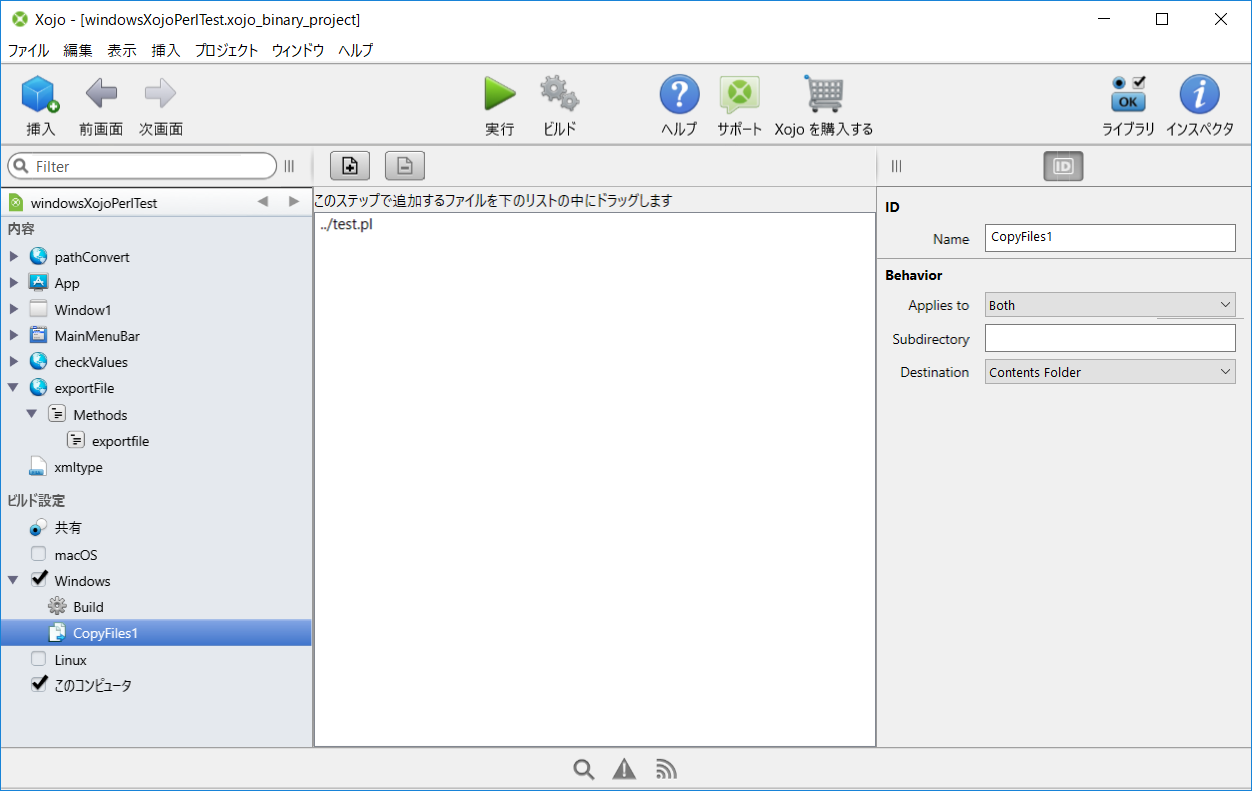 Macではアプリ自体実はフォルダなので、アプリ内のフォルダにPerlのスクリプトをコピーしていたのですが、Winではそういう扱いにならないようなので実行ファイルと同じ階層にコピーする指定をします。で配布時には親フォルダごと渡す。まあ一般的なやつですね。ビルド設定のWindowsのところでビルドステップに「ファイルのコピー」を追加してやり、ウィンドウにコピーするファイルをドラッグアンドドロップしてコピー先に「Contents Folder」を指定すればいいようです。なおサブディレクトリ作ってそこにコピーする指定もできる模様。
Macではアプリ自体実はフォルダなので、アプリ内のフォルダにPerlのスクリプトをコピーしていたのですが、Winではそういう扱いにならないようなので実行ファイルと同じ階層にコピーする指定をします。で配布時には親フォルダごと渡す。まあ一般的なやつですね。ビルド設定のWindowsのところでビルドステップに「ファイルのコピー」を追加してやり、ウィンドウにコピーするファイルをドラッグアンドドロップしてコピー先に「Contents Folder」を指定すればいいようです。なおサブディレクトリ作ってそこにコピーする指定もできる模様。
XojoからPerlにシェル経由で処理を投げて実行
あとはXojoからPerlにシェル経由で処理を投げるだけですが、Macとはフォルダの階層が異なるのと、StrawberryPerlの場合はBashではなくコマンドプロンプトに処理を投げることになるためパスやパイプ(コマンド連続実行)の記法が異なることに注意が必要なようです。具体的にはパスはシングルクォートではなくダブルクォートで囲まないとエラーになりますし、パイプに使う記号は「;」ではなく「&」です。なおXojo内でFolderItemのパスを「.NativePath」でString値として取得するとシングルクォートで囲まれた形でパスの文字列が返ってきてしまうので、変換してやらないと処理が通りません。ということでコードは以下のような感じ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
'実行している自身のパスを得る Dim App as new Application Dim SelfPath As FolderItem SelfPath = App.ExecutableFile '親フォルダのパスを得る Dim parentFolderPath As FolderItem = GetFolderItem( SelfPath.NativePath ).parent Dim parentFolderPathString As String = convertSingleqw2Doubleqw(parentFolderPath.NativePath) 'XMLファイルのパスを取得 Dim xmlFilePathString As String xmlFilePathString = Window1.filePath.Text 'perlに投げて出力 Dim exportFileCmd As String = "cd " + parentFolderPathString + " & perl test.pl " + &u22 + xmlFilePathString + &u22 Dim Sh As New Shell Sh.Execute(exportFileCmd) |
シングルクォートをダブルクォートに変換するメソッドは以下のような感じ。なお引数pathStringをString型で定義していて、戻り値もString型で返す感じ。
|
1 2 3 4 5 6 7 |
Dim re as New RegEx re.SearchPattern = "^&u27(.*?)&u27$" re.ReplacementPattern = "$1" re.Options.ReplaceAllMatches = True Dim convertedPath As String = re.Replace(pathString) convertedPath = &u22 + convertedPath + &u22 return convertedPath |
ここもうちょいスマートな感じで処理できればなと思うんですけどね。正規表現でゴリゴリ変換ってすごく泥臭い。
(2017.9.25)