Mac、Winともに使用することは可能ですが、環境によってはモジュールの追加インストールが必要になるかも知れません。私の環境ではWindowsのActivePerl環境にMinGWモジュールを追加インストールする必要がありました(コマンドプロンプトで「ppm install MinGW」と入力)。
use utf8;
use Encode qw/encode decode/;
use File::Basename qw/basename dirname/;
use Archive::Zip;
use Archive::Extract;
use File::Path;
$epubFilePath = $ARGV[0];
$epubFilePath = decode(‘UTF-8’, $epubFilePath);
my $epubFileName = basename $epubFilePath;
my $epubpackage = Archive::Zip->new();
die unless $epubpackage->read($epubFilePath) == Archive::Zip::AZ_OK;
my @xhtmlfilePaths;
my @files = $epubpackage->members();
foreach my $file (@files) {
push(@xhtmlfilePaths,$file->fileName) if ($file->fileName =~ /^(.*?)\.xhtml$/);
}
my $uniqueFolderPath = ‘/tmp/’ . $epubFileName;
my $mynum = 1;
if (-d $uniqueFolderPath){
while (-d $uniqueFolderPath){
$uniqueFolderPath = (‘/tmp/’ . $epubFileName . ‘_’ . $mynum);
$mynum++;
}
}
my $epubArchive = Archive::Extract->new(archive => $epubFilePath,type => ‘zip’) or die;
$epubArchive->extract(to => $uniqueFolderPath);
our $finalSarrogatePairOutputLog = “”;
our $finalIVSOutputLog = “”;
our $finalIrregularSpaceOutputLog = “”;
foreach $myXhtmlfilePath (@xhtmlfilePaths){
&eachFileProceed($myXhtmlfilePath);
}
if ($finalSarrogatePairOutputLog eq “”){
$finalSarrogatePairOutputLog = ‘##SarrogatePair Character Check Result : ‘ . “\r\n” . ‘OK! Not Any SarrogatePair Characters in EPUB File!’;
} else {
$finalSarrogatePairOutputLog = ‘##SarrogatePair Character Check Result : ‘ . “\r\n” . $finalSarrogatePairOutputLog;
}
if ($finalIVSOutputLog eq “”){
$finalIVSOutputLog = ‘##Unicode IVS Character Check Result : ‘ . “\r\n” . ‘OK! Not Any Unicode IVS Characters in EPUB File!’;
} else {
$finalIVSOutputLog = ‘##Unicode IVS Character Check Result : ‘ . “\r\n” . $finalIVSOutputLog;
}
if ($finalIrregularSpaceOutputLog eq “”){
$finalIrregularSpaceOutputLog = ‘##Irregular Space Character Check Result : ‘ . “\r\n” . ‘OK! Not Any Irregular Space Characters in EPUB File!’;
} else {
$finalIrregularSpaceOutputLog = ‘##Irregular Space Character Check Result : ‘ . “\r\n” . $finalIrregularSpaceOutputLog;
}
rmtree($uniqueFolderPath);
my $logOutputPath = (dirname $epubFilePath) . ‘/EpubTotalDataCheck.log’;
$logOutputPath = encode(‘UTF-8’, $logOutputPath);
open(OUT,”>> $logOutputPath”);
my $finalFilename = ‘####Checked FileName : ‘ . “\r\n” . $epubFileName;
$finalFilename = encode(‘UTF-8’, $finalFilename);
print OUT $finalFilename . “\r\n\r\n”;
$finalSarrogatePairOutputLog = encode(‘UTF-8’, $finalSarrogatePairOutputLog);
print OUT $finalSarrogatePairOutputLog . “\r\n\r\n”;
$finalIVSOutputLog = encode(‘UTF-8’, $finalIVSOutputLog);
print OUT $finalIVSOutputLog . “\r\n\r\n”;
$finalIrregularSpaceOutputLog = encode(‘UTF-8’, $finalIrregularSpaceOutputLog);
print OUT $finalIrregularSpaceOutputLog . “\r\n\r\n”;
close (OUT);
exit;
sub eachFileProceed {
my $myXhtmlfilePath = $_[0];
#各xhtmlファイル名を取得
our $xhtmlFileName = basename $myXhtmlfilePath;
my $eachFilePath = ($uniqueFolderPath . “/” . $myXhtmlfilePath);
open(IN,”$eachFilePath”);
#改行コードの統一処理
@myCHECKFILEtxts = ;
$myCHECKFILEtxts = join(“”,@myCHECKFILEtxts);
$myCHECKFILEtxts =~ s@\x0D\x0A@\x0D@g;
$myCHECKFILEtxts =~ s@\x0A@\x0D@g;
$myCHECKFILEtxts = decode(‘UTF-8’, $myCHECKFILEtxts);
@eachLine = split(“\x0D”,$myCHECKFILEtxts);
close (IN);
our $lineNumCount = 1;
foreach $myLine (@eachLine){
&eachLineProceed($myLine);
$lineNumCount++;
}
}
sub eachLineProceed {
my $myLine = $_[0];
while($myLine =~ /&\#x2[0-9A-Z]{4};/ig) {
$matchPlace = pos($myLine);
$finalSarrogatePairOutputLog = ($finalSarrogatePairOutputLog . ‘Caution! SarrogatePairCharacterRefernce at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $matchPlace . “\n”)
}
while($myLine =~ /&\#(1[0-9]{5});/ig) {
$matchPlace = pos($myLine);
if ($1 >= 131072 && $1 <= 196607) {
$finalSarrogatePairOutputLog = ($finalSarrogatePairOutputLog . ‘Caution! SarrogatePairCharacterRefernce at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $matchPlace . “\n”)
}
}
while($myLine =~ /&\#xE[0-9A-Z]{4};/ig) {
$matchPlace = pos($myLine);
$finalIVSOutputLog = ($finalIVSOutputLog . ‘Caution! UnicodeIVSCharacterRefernce at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $matchPlace . “\n”)
}
while($myLine =~ /&\#(9[0-9]{5});/ig) {
$matchPlace = pos($myLine);
if ($1 >= 917504 && $1 <= 983039) {
$finalIVSOutputLog = ($finalIVSOutputLog . ‘Caution! UnicodeIVSCharacterRefernce at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $matchPlace . “\n”)
}
}
while($myLine =~ /&\#x(200[456789ACD]);/ig) {
$matchPlace = pos($myLine);
$finalIrregularSpaceOutputLog = ($finalIrregularSpaceOutputLog . ‘Caution! IrregularSpaceCharactorRefernce at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $matchPlace . “\n”)
}
while($myLine =~ /&\#(819[6789]|820[01245]);/ig) {
$matchPlace = pos($myLine);
$finalIrregularSpaceOutputLog = ($finalIrregularSpaceOutputLog . ‘Caution! IrregularSpaceCharactorRefernce at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $matchPlace . “\n”)
}
my @eachchara = split(//,$myLine);
our $CharaNumCount = 1;
foreach $mychara(@eachchara){
&eachCharaProceed($myChara);
$CharaNumCount++;
}
}
sub eachCharaProceed {
my $myChara = $_[0];
if ($mychara =~ /[\x{20000}-\x{2FFFF}]/){
$finalSarrogatePairOutputLog = ($finalSarrogatePairOutputLog . ‘Caution! SarrogatePairCharacter at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $CharaNumCount . “\n”)
}
if ($mychara =~ /[\x{E0000}-\x{EFFFF}]/){
$finalIVSOutputLog = ($finalIVSOutputLog . ‘Caution! UnicodeIVSCharacter at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $CharaNumCount . “\n”)
}
if ($mychara =~ /[\x{2004}-\x{200A}\x{200C}-\x{200D}]/){
$finalIrregularSpaceOutputLog = ($finalIrregularSpaceOutputLog . ‘Caution! IrregularSpaceCharactor at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $CharaNumCount . “\n”)
}
}
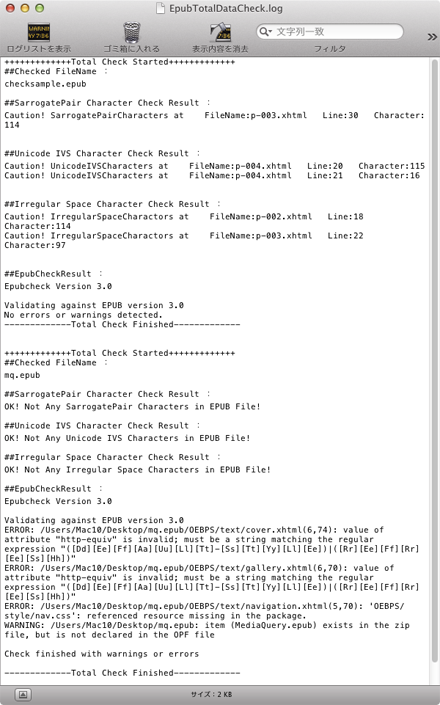
なお、Mac用にはEPUBCheck 3.0を組み込み、同時にログ出力できるようにしたドロップレットを作ってみました。Mac OS X 10.6/10.7/10.8で動作を確認しています。Mac OS X 10.5でも動作自体はしたのですが、Perlの呼び出しでエラーが出ました。Perlのアップデートが必要になると思われます。
Mac版ドロップレットはIVS/サロゲートペア文字のチェックとEPUBCheckを連続実行しますので、多数のepubファイルをまとめてチェックすると多少の時間がかかります。チェック結果は、epubファイルと同じ場所に出力される「EpubTotalDataCheck.log」で一括確認できます。既に同名のファイルが存在していた場合は末尾に追記します。