facebookの日本語EPUBマークアップ指針「JBasic」のグループで公開させていただいた関係者向けのInDesign CS5→JBasic08準拠のEPUB3.0用xhtml変換ワークフローです。こちらの詳細版になります。ご好評いただいたので一部補筆して再公開させていただきます。
テンプレート/変換スクリプト/サンプルコンテンツは以下のリンクからダウンロードしていただけます。
また、JBasicの資料はepubcaféよりあらかじめダウンロードした上でお読みください。
Indesign CS5作成環境はMac OS10.6、xml変換用スクリプトはWindows環境用です(Windows Vistaにて動作確認済)。ワークフロー/スクリプトを参照したことによって発生したコンテンツの破損等に関して弊社では責任を負いかねますのでご了承ください。
画像はクリックでポップアップ拡大表示されます。
◇
1 InDesign CS5の元ドキュメントを準備します
旧バージョンのInDesignで作成されたコンテンツなどはInDesign CS5で開き、別名保存して準備を整えておきます。
2 すべてのスタイルをインポートします
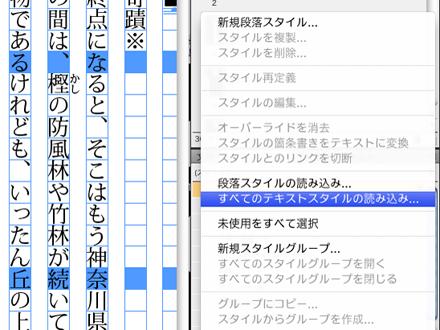 段落スタイルパレットもしくは文字スタイルパレットのメニューから「すべてのテキストスタイルの読み込み」を選択し、段落/文字スタイルテンプレート「ID5XML2JBASIC08_StyleTemplate.indd」からすべてのスタイルをインポートします。
段落スタイルパレットもしくは文字スタイルパレットのメニューから「すべてのテキストスタイルの読み込み」を選択し、段落/文字スタイルテンプレート「ID5XML2JBASIC08_StyleTemplate.indd」からすべてのスタイルをインポートします。
3 InDesignドキュメントを整備します
以下の形でInDesignドキュメントを整備します。
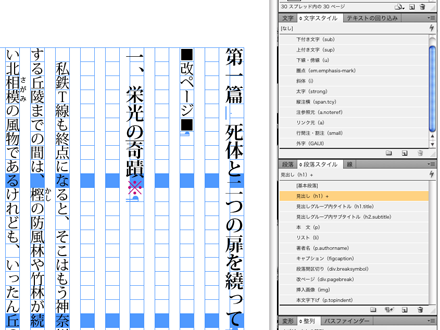 全ての行に段落スタイルを適用します。JBasic08では見出し(h1)のサイズは、「どのsection の下に置かれている見出しか」をcssが判断して決定する方針のようですので、部・章・節、どの見出しであっても全て同一の「見出し」スタイルをあてて構いません。カバー見出し、本扉見出し、メイン見出しの脇にサブ見出しがある場合などはそれぞれ別のスタイルをあてておき、JBasic08資料P22を参考に6でxml整形処理します。本文で複数のスタイルが混在するような場合は、適宜別のスタイルを作成して割り当てておきます。
全ての行に段落スタイルを適用します。JBasic08では見出し(h1)のサイズは、「どのsection の下に置かれている見出しか」をcssが判断して決定する方針のようですので、部・章・節、どの見出しであっても全て同一の「見出し」スタイルをあてて構いません。カバー見出し、本扉見出し、メイン見出しの脇にサブ見出しがある場合などはそれぞれ別のスタイルをあてておき、JBasic08資料P22を参考に6でxml整形処理します。本文で複数のスタイルが混在するような場合は、適宜別のスタイルを作成して割り当てておきます。
InDesignの段落/文字スタイル設定でのインデント/文字修飾等の各種定義要素は書き出したコンテンツに反映されませんので、極論しますと「スタイルが当たっていさえすればよい」のですが、EPUB作成にInDesignを用いることの大きなメリットは「実際にどういった見かけになるか確認しながら作業を進められる」ことにあると思いますので、ある程度最終イメージに近い形でスタイル要素を定義しておくことをおすすめします。
必要ならばルビをつけ直します。ルビに関しては文字スタイルをつける必要はありません。なお、熟語ルビは自動処理で連続6文字までの置換に対応しました。6文字を越える場合は適宜分割してルビをふってください。
圏点/下線/下付き文字/上付き文字など文字修飾要素にそれぞれ文字スタイルを適用してください。文字サイズ・フォントなどを変更する部分にもそれぞれ文字スタイルを適用してください(全ての文字装飾に文字スタイルを当てます)。文字パレット等を用いてInDesign内で個々の文字に文字修飾を加えても、タグの割り当てをしない限り書き出したxhtmlファイルには文字修飾効果が反映されませんので、必ず「文字スタイル」を用いて文字修飾を適用するようにしてください。
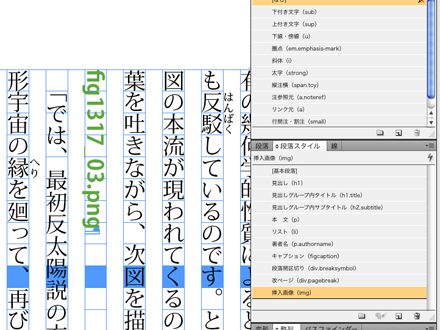 画像は「ファイル名」を拡張子込みで記述し、段落スタイルを当てます。(/OEBPS/images内に画像が収納されていることを前提に10でパスを付加します)
画像は「ファイル名」を拡張子込みで記述し、段落スタイルを当てます。(/OEBPS/images内に画像が収納されていることを前提に10でパスを付加します)
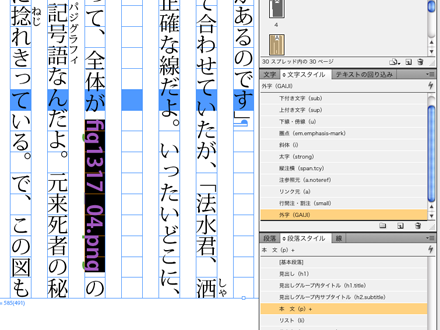 外字は「ファイル名」を拡張子込みで挿入部分に記述し、文字スタイルを当てます。(/OEBPS/images内に画像が収納されていることを前提に10でパスを付加します)
外字は「ファイル名」を拡張子込みで挿入部分に記述し、文字スタイルを当てます。(/OEBPS/images内に画像が収納されていることを前提に10でパスを付加します)
改ページ行は改ページ用の段落スタイルを当てておきます。10で変換した際、div.pagebreakタグを割り当てられた部分のテキストは10で電子書籍/webブラウザ上で表示されないコメント文に置換しますので、わかりやすく行内に「■改ページ(書籍○○ページ)■」などと入力しておいても構いません。
二倍ダーシなどの分離禁止処理は、ルビ文字にスペース1文字を入れたグループルビをあてて処理します。
太字部分内縦注横など、InDesignの仕様上同じ文字に複数の文字スタイルを適用できない部分に関しては、7で処理します。ここでは外側の要素(前述例の「太字」にあたる要素)のスタイルのみを当てておきます。
4 タグテンプレートからタグを読み込みます
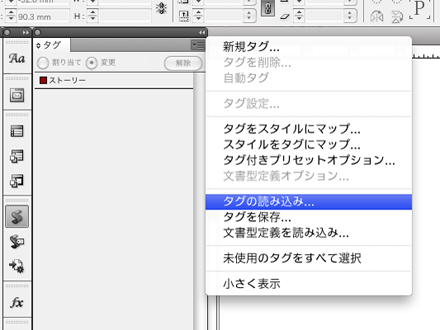 「タグ」パレットメニューから「タグの読み込み」を選択し、タグテンプレート「ID5XML2JBASIC08_TagTemplate.xml」からタグを読み込みます。
「タグ」パレットメニューから「タグの読み込み」を選択し、タグテンプレート「ID5XML2JBASIC08_TagTemplate.xml」からタグを読み込みます。
5 スタイルに自動でタグを割り当てます
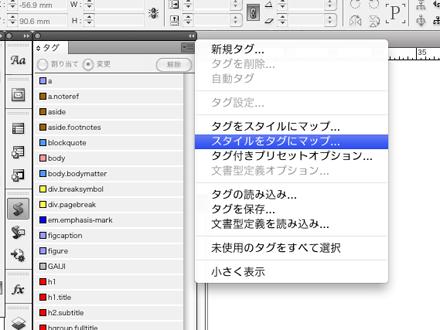 「タグ」パレットメニューから「スタイルをタグにマップ」を選択し、全ての段落スタイル及び文字スタイルに自動でタグを割り当てます。各スタイルに適合するタグがなかった場合は適宜作成した上で割り当てます。
「タグ」パレットメニューから「スタイルをタグにマップ」を選択し、全ての段落スタイル及び文字スタイルに自動でタグを割り当てます。各スタイルに適合するタグがなかった場合は適宜作成した上で割り当てます。
なお、「section.chapter」「p.authorname」のように「基本タグ+区切り文字+class名」の書式でタグ名を書くことで、10の変換時に自動処理で「class」および「epub:type」が付加されるようにスクリプト処理します。区切り文字には「.」および「-」および「_」が使用可能です。class名は任意ですが、可能な限りJbasic08内で規定されている値を用いることとします。なお、互換性を考えると全角文字は使わない方が無難です。
自動処理でclass およびepub:type の付くタグ
body section aside article nav h1 h2 h3 h4 h5 h6 hgroup a
自動処理でclass のみが付加されるタグ
p blockquote span em strong i u small figure figcaption div header footer ol ul li table tr td
6 「構造」ウィンドウでsectionなどを割り当てます
 InDesignの「構造」ウィンドウを表示させ、sectionなどの構造タグを割り当てていきます。ウィンドウ内に一覧表示されたタグ内で目的の構造タグに含めたいタグを全て選択し、「構造」ウィンドウのドロップダウンメニューもしくはコンテキストメニューから「新規親要素」を選択して割り当てます。
InDesignの「構造」ウィンドウを表示させ、sectionなどの構造タグを割り当てていきます。ウィンドウ内に一覧表示されたタグ内で目的の構造タグに含めたいタグを全て選択し、「構造」ウィンドウのドロップダウンメニューもしくはコンテキストメニューから「新規親要素」を選択して割り当てます。
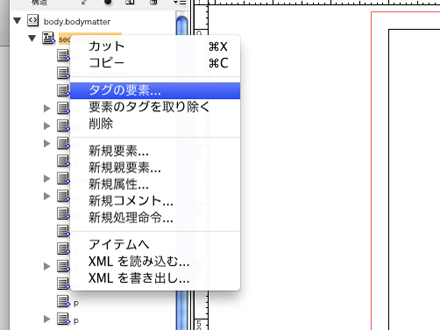 構造タグの種類そのものを変更したい場合は、「タグの要素」を選択して変更できます。構造タグを削除したい場合は「要素のタグを取り除く」を選択して削除できます。
構造タグの種類そのものを変更したい場合は、「タグの要素」を選択して変更できます。構造タグを削除したい場合は「要素のタグを取り除く」を選択して削除できます。
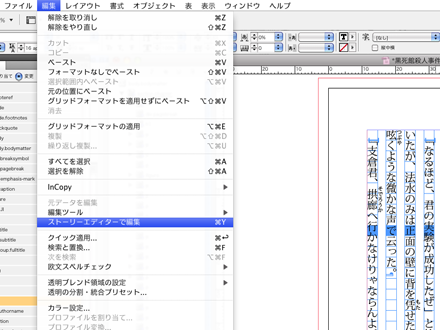 テキストの中身を確認しながらタグを付加したい場合には「ストーリーエディタ」を使うことで効率的に作業を行うことができます。ストーリーエディタはテキストフレーム内にカーソルを表示させた状態で「編集」メニュー→「ストーリーエディタで編集」で呼び出すことができます。ストーリーエディタ上でタグを付加したい部分を選択し、「タグ」パレットで付加したいタグをクリックすることで構造タグ付けが行えます。
テキストの中身を確認しながらタグを付加したい場合には「ストーリーエディタ」を使うことで効率的に作業を行うことができます。ストーリーエディタはテキストフレーム内にカーソルを表示させた状態で「編集」メニュー→「ストーリーエディタで編集」で呼び出すことができます。ストーリーエディタ上でタグを付加したい部分を選択し、「タグ」パレットで付加したいタグをクリックすることで構造タグ付けが行えます。
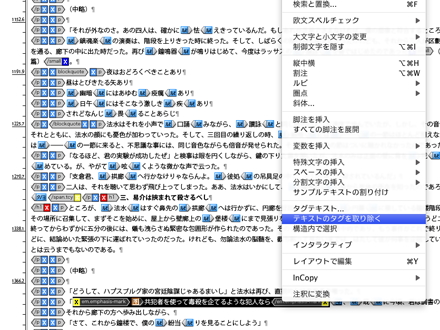 ストーリーエディタ上で誤ってタグを付加してしまった場合には、あらかじめ該当部分のテキストを選択した状態で、コンテキストメニューから「テキストのタグを取り除く」を選択することでタグを削除できます。
ストーリーエディタ上で誤ってタグを付加してしまった場合には、あらかじめ該当部分のテキストを選択した状態で、コンテキストメニューから「テキストのタグを取り除く」を選択することでタグを削除できます。
ここで割り当てる必要のある構造タグ要素
body section blockquote aside article nav figure hgroup header footer dl ol ul table div
段落間区切り(div.breaksymbol)および改ページ(div.pagebreak)は10で自動処理するため除きます
7 文字スタイルを重ねて適用できなかった箇所にタグを割り当てます
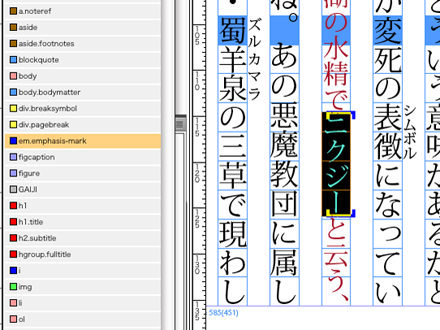 太字部分内の縦注横、行間注内の圏点などは、InDesignの仕様上同じ文字に複数の文字スタイルを適用できないため、4で自動でタグ付けができません。該当する文字を選択し、「タグ」パレットを使用して個々にタグを割り当てます(文字列を選択している状態で付加したいタグをクリックすればOKです)
太字部分内の縦注横、行間注内の圏点などは、InDesignの仕様上同じ文字に複数の文字スタイルを適用できないため、4で自動でタグ付けができません。該当する文字を選択し、「タグ」パレットを使用して個々にタグを割り当てます(文字列を選択している状態で付加したいタグをクリックすればOKです)
8 XML属性を付加します
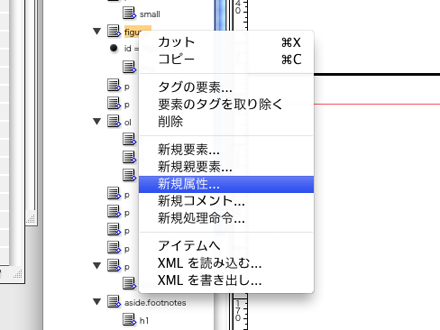 「構造」ウィンドウのタグ一覧から属性を付加したいタグを選択し、ドロップダウンメニューもしくはコンテキストメニューから「新規属性」を選択して各タグにid、name などのxml属性を割り当てます。「a」タグのリンク先、「figure」タグのid などはここで割り当てます。
「構造」ウィンドウのタグ一覧から属性を付加したいタグを選択し、ドロップダウンメニューもしくはコンテキストメニューから「新規属性」を選択して各タグにid、name などのxml属性を割り当てます。「a」タグのリンク先、「figure」タグのid などはここで割り当てます。
ここまでの情報を適用済のサンプルドキュメント(TaggingSampleDocument.indd)を同梱しておきますので、ご参照ください。
9 XML ファイルを書き出します
「ファイル」メニュー「書き出し」→フォーマット「XML」でXMLファイルを書き出します。
書き出し時のオプションは以下の通りです。
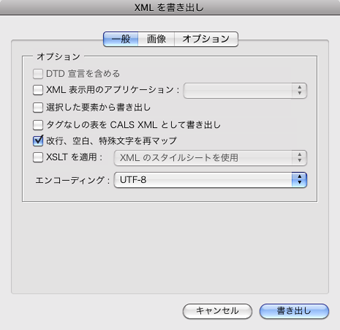 『一般』タブ
『一般』タブ
「改行、空白、特殊文字を再マップ」をチェック、他の全てチェックボックスは全てチェックしないでください。エンコーディングは「UTF-8」です。
「改行、空白、特殊文字を再マップ」をチェックしないとテキスト内の変な位置で改行されてしまい後処理に手間がかかりますので、チェックして改行なしで出力しスクリプトで改行を処理します。
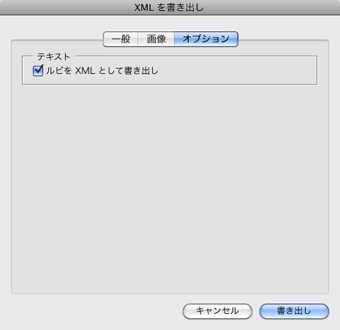 『画像』タブ
『画像』タブ
全てチェックしないでください。
『オプション』タブ
「ルビをXMLとして書き出し」をチェックしてください。
10 書き出したファイルを変換します
Windowsマシン上でスクリプトと同一のフォルダに入れたバッチファイル「ID5XML2Jbasic08.bat」に9で作成したxmlファイルをドラッグ&ドロップするとJBasic08準拠のxhtml元データに変換されます。(複数ファイルのドラッグ&ドロップには対応させていませんのでひとつずつ変換してください。)ルビ等はここでEPUB3準拠のタグ形式に置換されます。
なお、フリーのWindows用Perl環境、ActivePerlのインストールが別途必要となります。
ActivePerlはActiveState社ホームページ(http://www.activestate.com/)からダウンロードできます(トップページからPRODUCTS→ActivePerl→PPM/Perl Modules→Free Downloadsと進んでください)。
追記:Mac環境用置換スクリプトも作成しました。フリーで利用できるテキストエディタ「mi」にて作成したxmlファイルを開き、スクリプトを実行することでタグが置換されます。Mac OS 10.7/mi 2.1.11r1にてテスト済です。スクリプトは以下のリンクよりダウンロードしていただけます。
11 xmlファイルをepubに整形処理します
 書き出したコンテンツの<body>〜</body>をコピーし、JBasic08用テンプレートに貼り付けるなどしてepub に整形処理します。テンプレートファイルはepubcafé(http://www.epubcafe.jp/)から単体で入手できるほか、電子書籍オーサリングソフト「Fusee β」(フューズネットワーク)にテンプレートとして含まれていますので、そちらを利用してepub3.0コンテンツの作成を行うことができます。
書き出したコンテンツの<body>〜</body>をコピーし、JBasic08用テンプレートに貼り付けるなどしてepub に整形処理します。テンプレートファイルはepubcafé(http://www.epubcafe.jp/)から単体で入手できるほか、電子書籍オーサリングソフト「Fusee β」(フューズネットワーク)にテンプレートとして含まれていますので、そちらを利用してepub3.0コンテンツの作成を行うことができます。
追記1:段落行頭字下げをcssのtext-indentで行っている場合に文中に外字画像を挿入すると、「何故か外字が1文字ずれてとなりの文字と重なる」現象がmac版safariおよびgoogle chromeで発生します。その行のみタグを<p style=”text-indent:0”>としてtext-indentによる字下げを打ち消し、全角スペースで行頭字下げを行うことで回避できます。ただしxhtml内にcssを記述するのはあくまで緊急回避措置で、表示と構造を分離するというcss/xhtml本来の意義からも、多用することは避けた方が賢明と考えています。
追記2:外字イメージにルビをふるのは自動では無理ですので、テキストエディタにて後処理してください。スクリプト改訂により対応しました。下記参照。
追記3:リンク対照文字にルビが振られているとリンクが正常に働かない現象がsafariで起きます。注へのリンクを合印で行うことでとりあえずは回避可能です。
追記4:Adobe Digital Editions Preview 1.8.1では熟語ルビが正常に表示されません(1文字目のルビだけ表示される)。全てモノルビとして処理することで回避できます。また、外字イメージ上のルビも表示されないようです。
追記5:ibooks で明朝体で表示するためには、META-INFに「com.apple.ibooks.display-options.xml」を入れる必要があります。
(2011.12時点での情報です)
◇
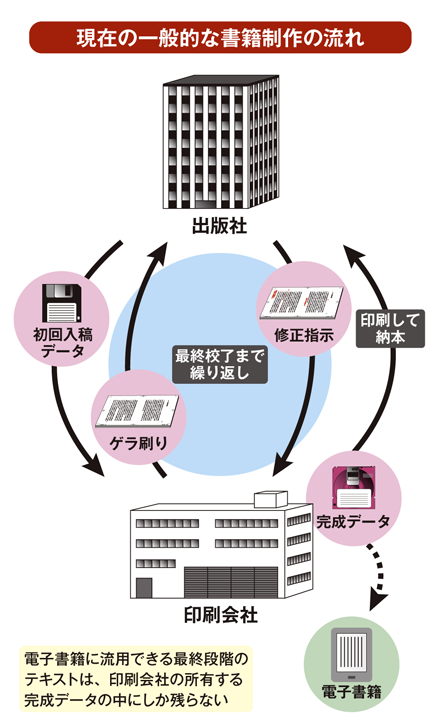
InDesignはCS3以降でEPUBの直接書き出しにも対応しているのですが、正直書き出されるXHTMLやCSSが綺麗とは言い難く、後編集の手間がかなり大変です。他のEPUB3簡易制作ソフトも試しましたが、ほぼ似たような状況です。Sigil、Fusie等を使用して手でタグを打ち込めばそのあたりの問題はクリアされますが、HTML/CSSの知識が個々に求められることになりますので、印刷系のオペレータにとってはかなり敷居が高くなってしまいます。可能であればすでに各オペレータが習熟済みのInDesign等を利用し、ワープロに近い感覚でEPUBを制作できれば良いと考えました。
そこで、InDesignのXML書き出し機能とPerlを組み合わせて、テキストエディタでの後編集の必要がほとんどない形に整形されたXHTMLのソースを取得し、別に用意しておいたCSSのファイルと組み合わせてEPUB3のコンテンツを作成する形でEPUB3を制作するフローチャートを考案してみたのがこちらになります。
整形されたXHTMLでEPUBを制作しておきませんと後々データの再利用の際に途方に暮れることにもなりそうですので、本気でビジネスとしてEPUB3コンテンツの制作を考えるならば、おそらくそのあたりは結構重要かと思います。EPUBに限らず、電子フォーマットはフォーマットとしての「賞味期限」は短いと考えた方が良いため、書籍のような長期間にわたって販売されるコンテンツの場合はデータ再利用を最初から頭に入れておくことが必要になると感じております。
また、InDesignのXML書き出し機能を利用する方式のメリットとして、「書き出せるのはEPUB用XHTMLに限らない」ということが挙げられます。XMDFなど他の電子書籍形式も内部的には全てXMLですので、読み込むテンプレートと置換スクリプトを差し替えるだけで全て同じ流れでコンテンツを制作できます(テスト済みです)。もちろんオーサリングソフトで最終的な編集は必要なのですが、かなりの省力化が可能です。2012年4月に発足する出版デジタル機構向けの中間フォーマットもこの流れで作成可能なのではないかと考えております(3月末現在、まだ仕様未公開のため確かなことは言えませんが・・・)。
なお、ここでInDesignを用いて行っている作業のかなりの部分を、InDesignと連携してテキスト編集を行うためのソリューション、「Adobe InCopy」で行うことができそうです。InCopyは1ライセンス新規購入でも3万円程度のソフトですので、InDesignと組み合わせて用いることで比較的安く多人数での電子書籍制作環境を構築できるかも知れません。InDesignとInCopyを連携させたXHTMLデータの制作については、いずれこのブログ内でレポートするつもりでおります。
(2012.3.27)
InDesignで一度ルビを入力した後、ルビを削除すると残ってしまう「空のルビタグ」を削除するためにスクリプトを改訂いたしました。
(2012.4.24)
外字のルビ処理に対応するためにスクリプトを改訂いたしました。ドキュメント内外字ファイル名にグループルビを振っておくことで、外字ルビとして自動置換出力します。
(2012.8.07)
Mac用置換スクリプトで「<p.indent>〜」等の記述が正常に変換されないケースがあった問題を修正しました。
(2012.9.06)
step2でスタイルを読み込む際に、スタイルパレットサブメニューの「すべてのテキストスタイルの読み込み」ではなく、「タグ」パレットサブメニューの「スタイルをタグにマップ」内の「読み込み」ボタンを利用して読み込むことで、段落・文字スタイル情報/タグ情報/各スタイルとタグの紐付け情報が一括で読み込まれるようです。テンプレートに多数のスタイル・タグを設定している場合かなりの時間節約になります。
(2012.10.10)
収録サンプルを改訂しました。また、電書協仕様のサンプルを併録しました。
(2012.10.29)