表組みをCSV経由でXHTMLにしてみた
InDesignデータからのEPUB制作で、悩ましいポイントのひとつが「表組み」の対応です。InDesignのEPUB書き出し機能を使うことでInDesign内の表をテーブル形式で書き出すことはできますが、InDesignの表組み機能では、そもそもセルの内容が複数ページにまたがるような場合には分割して作る必要があり、これの修正には当然相応の手間がかかります。また、そもそも元データがInDesign内の表作成機能を使用して作られていないケースも多々あります。
また、現状多くのビューアでテーブル表示の対応が不完全で、これを受けて電書協ガイドではテーブル要素を非対応としているという現状もあります。このため、現在のEPUB作成では、現実的な解として表組みのページを画像として挿入しています。
ただ、この形では当然文字を拡大することはできませんし、将来的にはアクセシビリティ対応にも支障をきたしそうです。
そこで、InDesign内の表組みをCSV経由でXHTMLに変換することを考えてみました。CSV(カンマ区切りテキスト)は、ExcelやKeynoteから書き出して生成することができますので、InDesign内の表をコピーしてExcel等にペーストし、CSV形式で書き出してPerlで変換するという流れでワークフロー化することができます。Excel等の表計算ソフトであれば、比較的簡単に表の内容の編集・整理が可能ですので、かなり柔軟な処理ができると思います。
PerlでCSVを扱う際に問題になるのは各項目の分割(パース)で、項目内にカンマが含まれていないなら普通にsplit関数で分割できるのですが、含まれている場合には結構面倒なことになりますので、今回は素直にCSV用のモジュール「Text::CSV_XS」を使いました。cpanminusがインストール済みの環境であれば、ターミナルで
sudo cpanm Text::CSV_XS
と入力すればインストールできるはずです。
また、今回出力するXHTMLファイルは最初の項目と次の項目を全角スペース区切りで並べ、次行との区別のためにぶら下がりインデントを指定する形にしてみました。表ではなくなってしまいますが、これならばまあ表示できないビューアはありません。本当はtable要素なりdiv要素のdisplay:table指定なりを使いたいところですが、現状ではまあ仕方ありません。
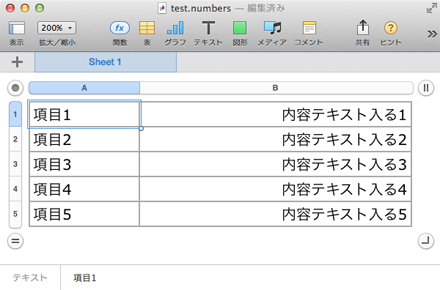 変換元データはこんな感じ。なお今回はPerl側で変換元の文字コードにUTF-8を指定しています。ExcelからCSVを出力した場合はShift_Jisで出力されるようですので、一度テキストエディタで開いて文字コードを変換する必要があります。なお、今回利用したNumbersでは出力時に文字コードを指定できる模様です。
変換元データはこんな感じ。なお今回はPerl側で変換元の文字コードにUTF-8を指定しています。ExcelからCSVを出力した場合はShift_Jisで出力されるようですので、一度テキストエディタで開いて文字コードを変換する必要があります。なお、今回利用したNumbersでは出力時に文字コードを指定できる模様です。
スクリプト的には外部からXHTMLのテンプレートを読み込む形にしても良いのですが、今回はコンパクトにしたかったのでソースコード内部に直にテンプレートを記述する形にしています。こういうのを「ヒアドキュメント」と呼ぶらしいです(初めて使いましたよ)。まあ可読性も良いですし悪くない形かなと思っています。以下が変換スクリプトになります。これに引数としてCSVファイルを食わせてやればXHTMLファイルを出力します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
#! /usr/bin/perl use utf8; use Encode qw/encode decode/; use Text::CSV_XS; ######################↓↓↓テンプレート(各行)↓↓↓###################### my $innerTemplate = <<'EOS'; <div class="h-indent-1em"> <p><span class="bold">XXXfirstitemXXX</span> XXXseconditemXXX</p> </div> EOS ######################↑↑↑テンプレート(各行)↑↑↑###################### ######################↓↓↓テンプレート(ヘッダフッタ)↓↓↓###################### my $outerTemplate = <<'EOS'; <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml" xmlns:epub="http://www.idpf.org/2007/ops" xml:lang="ja" class="vrtl" > <head> <meta charset="UTF-8"/> <title>作品名</title> <link rel="stylesheet" type="text/css" href="../style/book-style.css"/> </head> <body class="p-text"> <div class="main"> XXXinnerstringXXX </div> </body> </html> EOS ######################↑↑↑テンプレート(ヘッダフッタ)↑↑↑###################### ######################↓↓↓メイン部分↓↓↓###################### #変換Textファイルのパスを取得 my $convertCsvFilePath = $ARGV[0]; $convertCsvFilePath = decode('UTF-8', $convertCsvFilePath); #出力ファイルパスの定義 my $exportXhtmlFilePath = $convertCsvFilePath; $exportXhtmlFilePath =~ s@\.csv$@\.xhtml@; #各テキストファイルを展開、置換 open(IN,"$convertCsvFilePath"); #改行コードの統一処理 @eachLineTxts = <IN>; $eachLineTxt = join("",@eachLineTxts); $eachLineTxt =~ s@\x0D\x0A@\x0D@g; $eachLineTxt =~ s@\x0A@\x0D@g; @eachLineTxts = split("\x0D",$eachLineTxt); $joinedTxt = join("\x0D\x0A",@eachLineTxts); $joinedTxt = decode('UTF-8', $joinedTxt); close (IN); #置換処理 my $replacedTxt = & textReplace ($joinedTxt); #出力 $replacedTxt = encode('UTF-8', $replacedTxt); open(OUT,"> $exportXhtmlFilePath"); print OUT $replacedTxt; close (OUT); exit; ######################↑↑↑メイン部分↑↑↑###################### ######################↓↓↓変換サブルーチン↓↓↓###################### sub textReplace { #置換テキストの取得 $_ = $_[0]; #各行の置換処理 my @generatedLine; my @eachlines = split(/\x0D\x0A/,$_); foreach $eachline(@eachlines){ #Text::CSV_XSでcsvをパースして各パラメータを取り出す my $csvRef = Text::CSV_XS->new; $csvRef->parse($eachline); my @eachparameters = $csvRef->fields; my $firstItem = $eachparameters[0]; my $secondItem = $eachparameters[1]; #空欄なら処理せず、空欄でなければ各行テンプレートと合成 my $processingString = $innerTemplate; if ($firstItem eq ""){ next; } else { $processingString =~ s@XXXfirstitemXXX@$firstItem@; } if ($secondItem eq ""){ next; } else { $processingString =~ s@XXXseconditemXXX@$secondItem@; } push (@generatedLine,$processingString); } #各行を結合 $innerString = join("<p><br /></p>\x0D\x0A",@generatedLine); #ヘッダフッタ部分を合成 $_ = $outerTemplate; $_ =~ s@XXXinnerstringXXX@$innerString@; return $_; } ######################↑↑↑変換サブルーチン↑↑↑###################### |
出力結果はこんな感じ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml" xmlns:epub="http://www.idpf.org/2007/ops" xml:lang="ja" class="vrtl" > <head> <meta charset="UTF-8"/> <title>作品名</title> <link rel="stylesheet" type="text/css" href="../style/book-style.css"/> </head> <body class="p-text"> <div class="main"> <div class="h-indent-1em"> <p><span class="bold">項目1</span> 内容テキスト入る1</p> </div> <p><br /></p> <div class="h-indent-1em"> <p><span class="bold">項目2</span> 内容テキスト入る2</p> </div> <p><br /></p> <div class="h-indent-1em"> <p><span class="bold">項目3</span> 内容テキスト入る3</p> </div> <p><br /></p> <div class="h-indent-1em"> <p><span class="bold">項目4</span> 内容テキスト入る4</p> </div> <p><br /></p> <div class="h-indent-1em"> <p><span class="bold">項目5</span> 内容テキスト入る5</p> </div> </div> </body> </html> |
できたできた。
やっていることは比較的単純で、読み込んだCSVファイルの各行の項目をモジュールで分割し、各行のテンプレートに入れ込む処理をしてから合成済みのテキストを配列に収納し、最後に配列内の各行を結合しています。その後でヘッダフッタを合成。テンプレート部分を書き換えるだけでそれなりに便利に使えるかと思います。いずれEPUBでテーブルが普通に使用できるようになったとしても、まあ応用は効きそうかなと思っています。
(2014.9.16)
