テキストエディタ「mi」用「電書協EPUB用XHTML」モード
2013/06/26
「ツール」全メニュー一覧
これでは時間もかかる上に、電書協EPUB3制作ガイドの規定プロパティを活かしきることはできません。
そこで、Mac用テキストエディタ「mi」(旧名ミミカキエディット)の「モード」機能を利用し、デフォルトで選択できる「HTML」モードをもとに電書協EPUB3制作ガイド(緊デジリフローテンプレート)で規定された全てのプロパティ要素をメニューからのドロップダウン選択だけで入力できる「電書協EPUB用XHTML」モードを作ってみました。
また、特に修正に多大な労力を要する「ルビ」の修正につきましては、イースト株式会社の高瀬拓史(@lost_and_found)さん作の「でんでんコンバーター」のマークダウン記法、「でんでんマークダウン」のルビ記法とXHTMLのルビタグを相互に変換できる機能を収録し、可読性の高い、容易なルビ修正を実現しました。
さらに、縦組み時に正立・横転の指定が必要な記号類への自動タグ付加や、3桁までの半角数字への縦中横タグ自動付加、選択した段落への<p>〜</p>タグの自動付加、HTMLコメントの一括消去などもスクリプト化して収録しました。
MacでのEPUB制作のおともにお役立ていただければ嬉しいです。
ダウンロードはこちら(mi2.1用)
>>電書協EPUB用XHTMLモード(mi2用)
1 file(s) 1.41 MB
Mac OS X 10.7/10.8、mi 2.1.12r3にて動作確認済みです
ダウンロードはこちら(mi3.0用)
>>電書協EPUB用XHTML(mi3用)
1 file(s) 889.11 KB
macOS 10.13にて動作確認済みです
mi本体はこちらより入手できます。なお3.0用にはタグ以外の箇所の半角⇔→全角、カナ⇔かなの変換機能を追加しています。くわしくはこちら。
※既にmi2.1でこのモードを使用していた場合、mi3.0をインストールした際に自動で旧モードが取り込まれるのですが、これで取り込まれた旧モードは3.0用ではないため選択するとアプリが落ちてしまうようです。その場合はFinderの「移動」→「フォルダへ移動」から「/Users/■■■ユーザーネーム入れる■■■/Library/Application Support/mi3/mode/」でモードフォルダに移動して手動で古いモードを削除し、あらためて読み込んでみてください。
インストール
1 ダウンロードしたZIPパッケージをあらかじめ任意の場所に解凍しておきます。
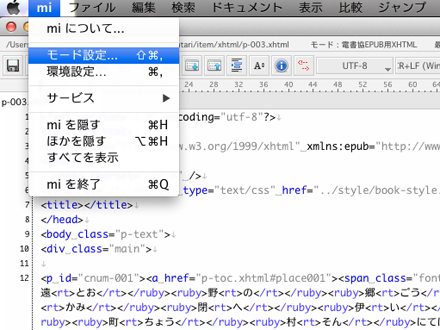 2 メニュー項目「mi」から「モード設定」を選択し、ウィンドウを開きます。
2 メニュー項目「mi」から「モード設定」を選択し、ウィンドウを開きます。
3 「モード追加」→ラジオボタン「新規」が選択されている状態で「ファイル選択」をクリックします(このとき、ラジオボタン「モードファイルからインポート」を選択してファイル選択ウィンドウを開くと、ステップ4で目的のファイルがグレーアウトして選択出来ない状態になることがあるようです)。
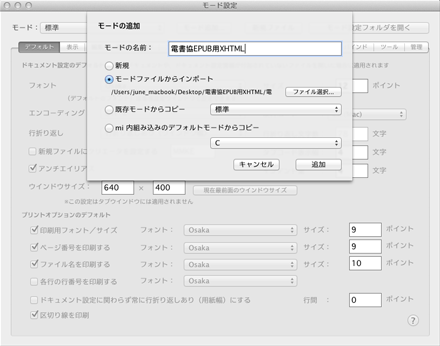 4 ダウンロードしたZIPパッケージ内のファイル「電書協EPUB用XHTML」を指定し、「追加」をクリックします。
4 ダウンロードしたZIPパッケージ内のファイル「電書協EPUB用XHTML」を指定し、「追加」をクリックします。
※mi3.0ではフォルダを選択する仕様になったようです
 5 「インポートしようとしているモード/ツールには〜」というメッセージが表示されるので、「インポート」を選択してインポートします。
5 「インポートしようとしているモード/ツールには〜」というメッセージが表示されるので、「インポート」を選択してインポートします。
6 メニュー項目「ドキュメント」→「モード」から「電書協EPUB用XHTML」が選択出来るようになります。
各機能説明(簡易マニュアル)
でんでんマークダウンのルビ記法←→XHTMLルビタグの相互変換
 変換したい範囲のテキストを選択し、「ツール」→「その他」から「XHTMLルビタグ→でんでんルビ変換」を選択することで、複雑なXHTMLのルビタグを可読性の高いでんでんマークダウンのルビ記法に変換して修正作業を行うことができます。すべての修正が済んだら「でんでんルビ→XHTMLルビタグ変換」を用いて再びXHTMLルビタグに変換します。きちんとルビが修正されているかの確認は、「Command+R」でSafariを呼び出してXHTMLファイルを表示させればOKです。
変換したい範囲のテキストを選択し、「ツール」→「その他」から「XHTMLルビタグ→でんでんルビ変換」を選択することで、複雑なXHTMLのルビタグを可読性の高いでんでんマークダウンのルビ記法に変換して修正作業を行うことができます。すべての修正が済んだら「でんでんルビ→XHTMLルビタグ変換」を用いて再びXHTMLルビタグに変換します。きちんとルビが修正されているかの確認は、「Command+R」でSafariを呼び出してXHTMLファイルを表示させればOKです。
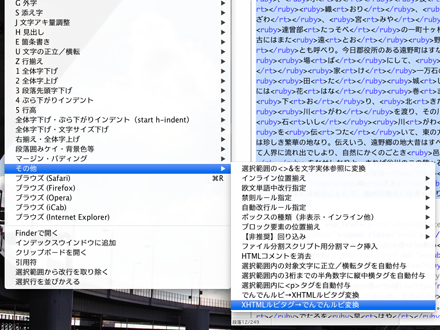 電書協ガイド仕様の外字イメージへのルビ付加にも対応しており、柔軟にルビの付加作業を行うことができます。
電書協ガイド仕様の外字イメージへのルビ付加にも対応しており、柔軟にルビの付加作業を行うことができます。
なお、でんでんマークダウンのルビ記法のルールはこちらをご参照ください。
正立・横転タグ自動付加
 選択範囲のテキスト内で縦組み時に文字回転(text-orientation)の指定が必要な文字を自動認識し、<span class=”upright”>/<span class=”sideways”>のタグを付加します。「ツール」→「その他」から「選択範囲内の対象文字に正立/横転タグを自動付与」を選択することで実行できます。
選択範囲のテキスト内で縦組み時に文字回転(text-orientation)の指定が必要な文字を自動認識し、<span class=”upright”>/<span class=”sideways”>のタグを付加します。「ツール」→「その他」から「選択範囲内の対象文字に正立/横転タグを自動付与」を選択することで実行できます。
なお、タグ付加が必要な文字はこちらの資料を参照しています。
3桁までの半角数字への縦中横タグ自動付加
選択範囲のテキスト内で全角文字に挟まれた3桁までの半角数字を認識し、自動で縦中横のタグを付加します。「ツール」→「その他」から「選択範囲内の3桁までの半角数字に縦中横タグを自動付与」を選択することで実行できます。
HTMLコメントを消去
選択範囲のテキスト内のHTMLコメント文を消去します。「ツール」→「その他」から「HTMLコメントを消去」を選択することで実行できます。
選択範囲内に<p>タグを自動付与
選択範囲内の段落に開始タグ「<p>」、終了タグ「</p>」を自動付与します。空改行は「<p><br /></p>」として処理します。「ツール」→「その他」から「選択範囲内に<p>タグを自動付与」を選択することで実行できます。
ファイル分割スクリプト用分割マーク挿入
文字列「<p>■分割■</p>」を挿入します。これは以前のエントリで紹介したファイル分割スクリプト「電書協仕様EPUB用XHTMLファイル分割」用のものです。「ツール」→「その他」から「ファイル分割スクリプト用分割マーク挿入」を選択することで実行できます。
基本構造(リフロー縦書き/リフロー横書き/フィックス)
「ツール」メニューの一番上に並んでいます。選択部分の前後に電書協ガイド仕様の各ヘッダ・フッタを付加します。基本的にCommand+Aでテキストを全体選択して使います。入力後のカーソルは<title></title>の間にありますので、そのままタイトルを入力できます。
項目グループ 見出し類
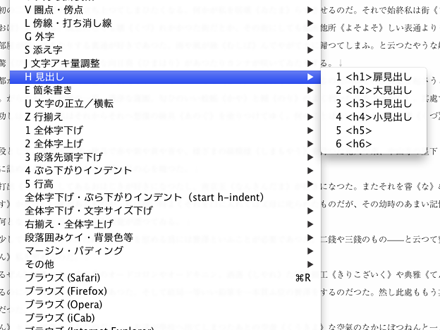 <h1>〜<h6>までの見出しタグを入力するための項目グループです。電書協EPUB3制作ガイドで規定されているクラス名、目次リンク用のID名が同時に挿入されます。ID番号は必要に応じて書き換えてください。
<h1>〜<h6>までの見出しタグを入力するための項目グループです。電書協EPUB3制作ガイドで規定されているクラス名、目次リンク用のID名が同時に挿入されます。ID番号は必要に応じて書き換えてください。
適用したい段落を選択し、各項目を選択することで前後に例えば以下のようなタグが挿入されます。
<h3 class=”naka-midashi” id=”toc-XXXXXXXXX”>見出しタイトル行</h3>
見出し以外の単体プロパティの入力項目については特に説明は必要ないと思われますので、省略いたします。
項目グループ 全体字下げ・ぶら下がりインデント
しばしば併用される複数のプロパティを同時入力するための項目グループです。全体○字下げ、ぶら下がり○字といったような表現を簡単に入力できます。
適用したい段落を選択し、項目を選択することで段落の前後に例えば以下のようなタグが挿入されます。
<div class=”start-1em”>
<div class=”h-indent-1em”>
<p>サンプルサンプルサンプルサンプルサンプルサンプル</p>
</div>
</div>
項目グループ 全体字下げ・文字サイズ下げ
しばしば併用される複数のプロパティを同時入力するための項目グループです。全体○字下げ、文字サイズ○%下げといったような表現を簡単に入力できます。
適用したい段落を選択し、項目を選択することで段落の前後に例えば以下のようなタグが挿入されます。
<div class=”start-1em”>
<div class=”font-090per”>
<p>サンプルサンプルサンプルサンプルサンプルサンプル</p>
</div>
</div>
項目グループ 右揃え・全体字上げ
しばしば併用される複数のプロパティを同時入力するための項目グループです。右(縦組では下)揃え、行末○字上げといったような表現を簡単に入力できます。
適用したい段落を選択し、項目を選択することで段落の前後に例えば以下のようなタグが挿入されます。
<div class=”align-right”>
<div class=”end-1em”>
<p>サンプルサンプルサンプルサンプルサンプルサンプル</p>
</div>
</div>
主なキーバインド(ショートカット)による文字挿入
文字を選択し、各キーバインドを入力することで以下のタグが挿入されます。
Control+B <span class=”bold”>選択文字</span>
Control+C <a class=”cyu” href=”#ref-XXX”>選択文字</a>
Control+G <span class=”gfont”>選択文字</span>
Control+K <span class=”key” id=”key-XXX”>選択文字</span>
Control+M <span class=”mfont”>選択文字</span>
Control+N <p><br /></p>
Control+O <span class=”upright-1″>選択文字</span>
Control+P <p>選択文字</p>
Control+R <ruby>選択文字<rt></rt></ruby>
Control+S <span class=”sideways”>選択文字</span>
Control+T <span class=”tcy”>選択文字</span>
Control+U <span class=”upright”>選択文字</span>
これはテキストエディタのカスタム機能ですので、モードの項目、キーバインド等気軽に追加、改訂することが可能です。使いやすいようにカスタマイズしてご活用ください。
(2013.6.26)
テキストエディタ「mi」の「モード/ツールライブラリ」にご掲載いただきました。mi開発者の上山さま、ありがとうございます。
(2013.9.9)
mi3.0用モードを追加しました。
(2018.6.21)




