#! /usr/bin/perl
use utf8;
use Encode qw/encode decode/;
use File::Basename qw/basename dirname/;
use File::Path;
use File::Find;
#EPUBフォルダのパスを取得、インポート
my $epubFolderPath = $ARGV[0];
$epubFolderPath = decode('UTF-8', $epubFolderPath);
#「この続きは〜」記述ファイルのパスを取得、インポート
my $pSampleFilePath = $ARGV[1];
$pSampleFilePath = decode('UTF-8', $pSampleFilePath);
###################EPUBフォルダを作業用フォルダにコピー###################
my $epubFileName = basename $epubFolderPath;
my $epubWorkFolderPath = '/tmp/' . "sample_" . $epubFileName;
my $epubFolderCopyCommand = "cp -R " . '"' . $epubFolderPath . '"' . " " . '"' . $epubWorkFolderPath . '"';
system $epubFolderCopyCommand;
###################各ファイルへのパス/ファイル名取得###################
#EPUB出力先のパスを取得
my $epubExportPath = dirname $epubFolderPath;
#OPF、Xhtml、imageの各ファイルへのパスを取得
my @opfFilePath;
my @xhtmlFilePath;
my @imageFilePath;
find(\&getEachFile, $epubWorkFolderPath);
#OPFファイルへのパス取得
my $opfFilePath = $opfFilePath[0];
#論理目次ファイルのファイル名取得
my $navFileName = &getNavFileName($opfFilePath);
#論理目次ファイルの絶対パス取得
my @navFilePathList;
find(\&getNavFile, $epubWorkFolderPath);
my $navFilePath = $navFilePathList[0];
#OPFのSpine指定をもとにEPUB内表示順にXHTMLファイルへのパスの配列を取得
my @spineFileList = &getSpineFileList($opfFilePath);
###################不要なファイルの削除処理###################
#XHTMLファイルを表示順で展開し、試し読み指示テキストが出てくる箇所でXHTMLファイルを分割/それ以後のXHTMLファイルを削除
my @existAndDeletedFileList = &cutXhtmlFile(@spineFileList);
#消さなかったXHTMLファイルのフルパス/消したXHTMLファイルのファイル名の各リストを取得
my @existFilePathList = @{$existAndDeletedFileList[0]};
my @deletedXhtmlFileList = @{$existAndDeletedFileList[1]};
#消さなかったXHTMLファイルを順番に展開し、リンクされているイメージファイルへのフルパスをリストとして取得
my @eachArray = (\@existFilePathList,$epubWorkFolderPath);
my @linkedImageFilesPathList = &getLinkedImageFile(@eachArray);
#要らないイメージファイルを消去
my @eachArray = (\@imageFilePath,\@linkedImageFilesPathList);
#消した画像ファイルのファイル名リストを取得
my @deletedImageFileList = &deleteUnlinkedImageFile(@eachArray);
###################不要なOPF行の削除処理###################
#OPFのManifest、Spineの整理、Titleへの「試し読み」文言挿入
my $xhtmlFolderPath = dirname $existFilePathList[0];
my @deletedAllFileList = (\@deletedXhtmlFileList,\@deletedImageFileList,$opfFilePath,$xhtmlFolderPath);
&opfCleanUp(@deletedAllFileList);
###################切れたリンクの削除処理###################
my @eachArray = (\@existFilePathList,\@deletedXhtmlFileList,$navFilePath);
&unmatchedLinkFix(@eachArray);
###################試し読みはここまでファイルの自動挿入処理###################
my $copySpotPath = $xhtmlFolderPath . "/p-sample.xhtml";
my @eachPath = ($pSampleFilePath,$copySpotPath,$opfFilePath);
&insertPsampleXhtml(@eachPath);
###################epubファイル作成処理###################
#出力先パスを取得
my $outputEpubName = basename $epubWorkFolderPath;
my $syscommand = 'cd ' . '"' . $epubWorkFolderPath . '"' . ';zip -0 -X '. '"../' . $outputEpubName . '.epub"' . ' mimetype;zip -r ' . '"../' . $outputEpubName . '.epub' . '"' . ' * -x mimetype */.DS_Store */*/.DS_Store */*/*/.DS_Store';
system $syscommand;
my $epubMoveTargetPath = dirname $epubFolderPath;
my $epubPreGenaratePath = $epubWorkFolderPath . $outputEpubName . '.epub';
my $epubMoveCommand = 'mv -f ' . '"' . $epubWorkFolderPath . ".epub" . '"' . " " . '"' . $epubMoveTargetPath . '"';
system $epubMoveCommand;
###################作業ファイルの削除処理###################
rmtree($epubWorkFolderPath);
exit;
#サブルーチン
sub getEachFile {
my $file = $_;
my $path = $File::Find::name;
push(@opfFilePath,$path) if ($path =~ /^(.*?)\.opf$/);
push(@xhtmlFilePath,$path) if ($path =~ /^(.*?)\.xhtml$/i);
push(@imageFilePath,$path) if ($path =~ /^(.*?)\.(jpg|jpeg|png|gif)$/i);
}
sub getNavFile {
my $file = $_;
my $path = $File::Find::name;
push(@navFilePathList,$path) if ($path =~ /^.*?\/$navFileName$/);
}
sub getSpineFileList {
my $opfFilePath = $_[0];
open(IN,"$opfFilePath");
#改行コードの統一処理
@eachLineOpfTxts = <IN>;
$eachLineOpfTxt = join("",@eachLineOpfTxts);
$eachLineOpfTxt =~ s@\x0D\x0A@\x0D@g;
$eachLineOpfTxt =~ s@\x0A@\x0D@g;
@eachLineOpfTxts = split("\x0D",$eachLineOpfTxt);
close (IN);
#SPINEのidrefを取得
my @idrefList;
foreach my $line(@eachLineOpfTxts) {
if ($line =~ /^.*?idref=\"(.*?)\".*?$/){
$line =~ s@^.*?idref=\"(.*?)\".*?$@$1@;
push(@idrefList,$line);
}
}
#SPINEのidrefをキーに各XHTMLファイルへのパスを取得
my $itemPath = dirname $opfFilePath;
my @spineFileList;
foreach my $idref(@idrefList){
my @href = grep /id=\"$idref\"/,@eachLineOpfTxts;
my $hrefPath = $href[0];
$hrefPath =~ s@^.*?href=\"(.*?)\".*?$@$1@;
$hrefPath = $itemPath . "/" . $hrefPath;
push(@spineFileList,$hrefPath);
}
return @spineFileList;
}
sub cutXhtmlFile {
my @spineFileList = @_;
our $sampleFileOutputFlag = "yet";
our @existFilePathList;
our @deletedFileList;
foreach $eachFilePath(@spineFileList){
$eachFilePath = encode('UTF-8', $eachFilePath);
#サンプルファイルがすでに出力されていたらファイルを削除する処理
if ($sampleFileOutputFlag eq "dune"){
#消去ファイルのリストにpush
$deleteFileName = basename $eachFilePath;
push(@deletedFileList,$deleteFileName);
unlink $eachFilePath;
} else {
#存在ファイルのリストにpush
$existFileName = basename $eachFilePath;
push(@existFilePathList,$eachFilePath);
open(IN,"$eachFilePath");
#改行コードの統一処理
@mySPLITFILEtxts = <IN>;
$mySPLITFILEtxts = join("",@mySPLITFILEtxts);
$mySPLITFILEtxts =~ s@\x0D\x0A@\x0D@g;
$mySPLITFILEtxts =~ s@\x0A@\x0D@g;
$mySPLITFILEtxts = decode('UTF-8', $mySPLITFILEtxts);
@eachLine = split("\x0D",$mySPLITFILEtxts);
close (IN);
#「++Trial reading is so far++」もしくは「++試し読みここまで++」という文が含まれる行が出てきたらそこまでの行を出力
my @outputTxt = ();
foreach $line (@eachLine){
if ($line =~ /(\+\+Trial reading is so far\+\+|\+\+試し読みここまで\+\+)/){
open(OUT,"> $eachFilePath");
foreach (@outputTxt){
$_ = encode('UTF-8', $_);
print OUT $_ . "\r\n";
}
close (OUT);
#html tidyで閉じタグ自動補正
my $fixXhtmlCommand = "tidy -xml -utf8 -m -q " . '"' . $eachFilePath . '"';
system $fixXhtmlCommand;
#tidyで修正後の改行コード関係修正
open(IN,"$eachFilePath");
#改行コードの統一処理
@myTxts = <IN>;
my $myTxts = join("",@myTxts);
$myTxts =~ s@\x0D\x0A@\x0D@g;
$myTxts =~ s@\x0A@\x0D@g;
@myTxts = split("\x0D",$myTxts);
$myTxt = join("\x0D\x0A",@myTxts);
$myTxt = decode('UTF-8', $myTxt);
close (IN);
#改行コード削除処理
my @blockObjectArray = qw/address center dir dl fieldset h1 h2 h3 h4 h5 h6 hr isindex menu noframes noscript ol p pre ul/;
my @inlineObjectArray = qw /a abbr acronym applet b basefont bdo big br button cite code dfn em font i iframe img input kbd label map object q s samp script select small span strike strong sub sup textarea tt u var/;
foreach $object(@blockObjectArray){
$myTxt =~ s@<$object([^<>]*?)>\x0D\x0A@<$object$1>@g;
$myTxt =~ s@\x0D\x0A</$object>@</$object>@g;
}
foreach $object(@inlineObjectArray){
$myTxt =~ s@\x0D\x0A<$object([^<>]*?)>\x0D\x0A@<$object$1>@g;
$myTxt =~ s@<$object([^<>]*?)>\x0D\x0A@<$object$1>@g;
$myTxt =~ s@\x0D\x0A<$object([^<>]*?)>@<$object$1>@g;
$myTxt =~ s@\x0D\x0A</$object>\x0D\x0A@</$object>@g;
$myTxt =~ s@\x0D\x0A</$object>@</$object>@g;
$myTxt =~ s@</$object>\x0D\x0A@</$object>@g;
}
$myTxt =~ s@\"\x0D\x0A@\" @g;
$myTxt =~ s@<body([^<>]*?)>@\x0D\x0A<body$1>\x0D\x0A@g;
#再出力
open(OUT,"> $eachFilePath");
$myTxt = encode('UTF-8', $myTxt);
print OUT $myTxt;
close (OUT);
$sampleFileOutputFlag = "dune";
last;
} else {
push(@outputTxt,$line);
}
}
}
}
my @existAndDeletedFileList = (\@existFilePathList,\@deletedFileList);
return @existAndDeletedFileList;
}
sub getLinkedImageFile {
my @existFilePathList = @{$_[0]};
my $epubFolderPath = $_[1];
my @linkedImageFilesList;
my @linkedImageFilesPathList;
foreach $eachExistFilePath(@existFilePathList){
open(IN,"$eachExistFilePath");
#改行コードの統一処理
@mySPLITFILEtxts = <IN>;
$mySPLITFILEtxts = join("",@mySPLITFILEtxts);
$mySPLITFILEtxts =~ s@\x0D\x0A@\x0D@g;
$mySPLITFILEtxts =~ s@\x0A@\x0D@g;
$mySPLITFILEtxts = decode('UTF-8', $mySPLITFILEtxts);
@eachLine = split("\x0D",$mySPLITFILEtxts);
my $joinedTxt = join("\x0D\x0A",@eachLine);
close (IN);
my @imageFileNames = ($joinedTxt =~ /([^\/]+\.jpg|[^\/]+\.JPG|[^\/]+\.jpeg|[^\/]+\.JPEG|[^\/]+\.png|[^\/]+\.PNG|[^\/]+\.gif|[^\/]+\.GIF)/g);
foreach $imageFileName (@imageFileNames){
find(\&getImageFilePath, $epubFolderPath);
sub getImageFilePath {
my $file = $_;
my $path = $File::Find::name;
push(@linkedImageFilesPathList,$path) if ($path =~ /.*?\/$imageFileName$/);
}
}
}
#重複削除
my %hash;
@hash{ @linkedImageFilesPathList } = ();
my @linkedImageFilesPathList = keys %hash;
return @linkedImageFilesPathList;
}
sub deleteUnlinkedImageFile {
my @imageFilePath = @{$_[0]};
my @linkedImageFilesPathList = @{$_[1]};
#配列の差分を出す
my %cnt = ();
map { $cnt{$_}-- } @linkedImageFilesPathList;
my @UnlinkedImageFilePathList = grep { ++$cnt{$_} == 1 } @imageFilePath;
my @deletedImageFilesList;
#いらなくなった画像ファイルを消す
foreach $UnlinkedImageFilePath (@UnlinkedImageFilePathList){
my $UnlinkedImageFileName = basename $UnlinkedImageFilePath;
push(@deletedImageFilesList,$UnlinkedImageFileName);
unlink $UnlinkedImageFilePath;
}
#消したファイル名を返す
return @deletedImageFilesList;
}
sub opfCleanUp {
my @deletedXhtmlFileList = @{$_[0]};
my @deletedImageFileList = @{$_[1]};
my $opfFilePath = $_[2];
my $xhtmlFolderPath = $_[3];
#######OPFのSPINE要素内の不要となったXHTMLファイルの宣言を削除#######
#OPFファイルを開く
open(IN,"$opfFilePath");
#改行コードの統一処理
@eachLineOpfTxts = <IN>;
$eachLineOpfTxt = join("",@eachLineOpfTxts);
$eachLineOpfTxt =~ s@\x0D\x0A@\x0D@g;
$eachLineOpfTxt =~ s@\x0A@\x0D@g;
@eachLineOpfTxts = split("\x0D",$eachLineOpfTxt);
close (IN);
#不要となった各XHTMLファイルに対応するidrefの取得
our @deletedIdrefList;
foreach my $eachDeletedFile(@deletedXhtmlFileList){
my @idrefLine = grep /(<item .*?id ?= ?\"(.*?)\"\ .*?href ?= ?\".*?$eachDeletedFile\".*?\/>|<item .*?href ?= ?\".*?$eachDeletedFile\" .*?id ?= ?\"(.*?)\".*?\/>)/,@eachLineOpfTxts;
my $idrefName = $idrefLine[0];
$idrefName =~ s@^.*?id ?= ?\"(.*?)\".*?$@$1@;
push(@deletedIdrefList,$idrefName);
}
#OPFのテキストを連結
our $joinedOpfText = join("\x0D\x0A",@eachLineOpfTxts);
$joinedOpfText = decode('UTF-8', $joinedOpfText);
#manifest(XHTML)の削除
foreach my $eachDeletedFile(@deletedXhtmlFileList){
$joinedOpfText =~ s@<item .*?href ?= ?\".*?$eachDeletedFile\".*?\/>\x0D\x0A@@;
}
#manifest(IMAGE)の削除
foreach my $eachDeletedFile(@deletedImageFileList){
$joinedOpfText =~ s@<item .*?href ?= ?\".*?$eachDeletedFile\".*?\/>\x0D\x0A@@;
}
#spineの削除
foreach my $eachIdrefName(@deletedIdrefList){
$joinedOpfText =~ s@<itemref .*?idref ?= ?\"$eachIdrefName\".*?\/>\x0D\x0A@@;
}
#Titleに「試し読み版」表記を追加
$joinedOpfText =~ s@<dc:title([^>]*?)>(.*?)</dc:title>@<dc:title$1>【試し読み版】$2</dc:title>@;
#manifestのxhtml部分に「p-sample.xhtml」追記
my $opfFileDirName = dirname $opfFilePath;
if ($opfFileDirName eq $xhtmlFolderPath){
$joinedOpfText =~ s@/>.*?(\x0D\x0A\x0D\x0A|\x0D\x0A).*?</manifest>@/>\x0D\x0A<item media-type="application/xhtml+xml" id="p-sample" href="p-sample.xhtml" />\x0D\x0A\x0D\x0A</manifest>@;
} else {
my $xhtmlFolderName = basename $xhtmlFolderPath;
$joinedOpfText =~ s@/>.*?(\x0D\x0A\x0D\x0A|\x0D\x0A).*?</manifest>@/>\x0D\x0A<item media-type="application/xhtml+xml" id="p-sample" href="$xhtmlFolderName/p-sample.xhtml" />\x0D\x0A\x0D\x0A</manifest>@;
}
#spine末尾に「p-sample」追記
$joinedOpfText =~ s@/>.*?(\x0D\x0A\x0D\x0A|\x0D\x0A).*?</spine>@/>\x0D\x0A<itemref linear="yes" idref="p-sample" />\x0D\x0A\x0D\x0A</spine>@;
#修正後のOPFファイルの出力
open(OUT,"> $opfFilePath");
$joinedOpfText = encode('UTF-8', $joinedOpfText);
print OUT $joinedOpfText;
close (OUT);
}
sub unmatchedLinkFix {
my @existFilePathList = @{$_[0]};
my @deletedXhtmlFileList = @{$_[1]};
my $navFilePath = $_[2];
#######################id名、リンク先ファイル名ピックアップ処理#######################
my @idList;
#フォルダ内各XHTMLファイルを開く繰り返し処理
foreach $eachXhtmlFilePath(@existFilePathList){
open(IN,"$eachXhtmlFilePath");
#改行コードの統一、各行をリストに収録
my @myTxts = <IN>;
my $myTxts = join("",@myTxts);
$myTxts =~ s@\x0D\x0A@\x0D@g;
$myTxts =~ s@\x0A@\x0D@g;
@myTxts = split("\x0D",$myTxts);
$myTxt = join("\x0D\x0A",@myTxts);
close (IN);
#id名をリストに収録
my @matchList = ($myTxt =~ /id=\"(.*?)\"/gs);
foreach $matchString(@matchList){
push (@idList,$matchString);
}
}
#######################論理目次ファイルのテキスト置換処理#######################
open(IN,"$navFilePath");
#改行コードの統一、各行をリストに収録
my @myNavTxts = <IN>;
my $myNavTxts = join("",@myNavTxts);
$myNavTxts =~ s@\x0D\x0A@\x0D@g;
$myNavTxts =~ s@\x0A@\x0D@g;
@myNavTxts = split("\x0D",$myNavTxts);
$myNavTxt = join("\x0D\x0A",@myNavTxts);
close (IN);
#消去済みのファイルへのリンクを削除
foreach $deletedXhtmlFile (@deletedXhtmlFileList){
$myNavTxt =~ s@<li><a.*?href=\"xhtml/$deletedXhtmlFile.*?\">.*?</a></li>\x0D\x0A@@;
}
#修正済みファイル出力処理
open(OUT,"> $navFilePath");
print OUT $myNavTxt;
close (OUT);
#######################各XHTMLファイルのテキスト置換処理#######################
#リンク元ファイルを検索、リンクに突き当たったら処理
foreach $eachXhtmlFilePath(@existFilePathList){
open(IN,"$eachXhtmlFilePath");
#改行コードの統一、各行をリストに収録
my @myTxts = <IN>;
my $myTxts = join("",@myTxts);
$myTxts =~ s@\x0D\x0A@\x0D@g;
$myTxts =~ s@\x0A@\x0D@g;
@myTxts = split("\x0D",$myTxts);
$myTxt = join("\x0D\x0A",@myTxts);
close (IN);
#アンカー指定されているリンクのアンカー部分をリストで取得
my @anchorLinkList = ($myTxt =~ /href ?= ?\".*?\#(.*?)\"/g);
#IDのリストにないアンカー指定されているリンクを削除
foreach $anchorID(@anchorLinkList){
unless (grep {$_ eq $anchorID} @idList){
$myTxt =~ s@<a.*?href ?= ?\".*?\#$anchorID\".*?>\x0D?\x0A?(.*?)\x0D?\x0A?<\/a>@$1@;
}
}
#消去済みのファイルへのリンクを削除
foreach $deletedXhtmlFile (@deletedXhtmlFileList){
$myTxt =~ s@<a.*?href=\"$deletedXhtmlFile.*?\">\x0D?\x0A?(.*?)\x0D?\x0A?</a>@$1@;
}
#修正済みファイル出力処理
open(OUT,"> $eachXhtmlFilePath");
print OUT $myTxt;
close (OUT);
}
}
sub getNavFileName {
my $opfFilePath = $_[0];
open(IN,"$opfFilePath");
#改行コードの統一処理
@eachLineOpfTxts = <IN>;
$eachLineOpfTxt = join("",@eachLineOpfTxts);
$eachLineOpfTxt =~ s@\x0D\x0A@\x0D@g;
$eachLineOpfTxt =~ s@\x0A@\x0D@g;
@eachLineOpfTxts = split("\x0D",$eachLineOpfTxt);
close (IN);
#navファイルへのパスを取得
my @navFileNameList;
foreach my $line(@eachLineOpfTxts) {
if ($line =~ /properties ?= ?\"nav\"/){
$line =~ s@^.*?href=\"(.*?)\".*?$@$1@;
push(@navFileNameList,$line);
}
}
$navFileName = $navFileNameList[0];
$navFileName = basename $navFileName;
return $navFileName;
}
sub insertPsampleXhtml {
my $pSampleFilePath = $_[0];
my $copySpotPath = $_[1];
my $opfFilePath = $_[2];
##############OPFを展開してタイトルを取得##############
#OPFファイルを開く
open(OPFIN,"$opfFilePath");
#改行コードの統一処理
@eachLineOpfTxts = <OPFIN>;
$eachLineOpfTxt = join("",@eachLineOpfTxts);
$eachLineOpfTxt =~ s@\x0D\x0A@\x0D@g;
$eachLineOpfTxt =~ s@\x0A@\x0D@g;
@eachLineOpfTxts = split("\x0D",$eachLineOpfTxt);
$eachLineOpfTxt = join("\x0D\x0A",@eachLineOpfTxts);
close (OPFIN);
$eachLineOpfTxt = decode('UTF-8', $eachLineOpfTxt);
my $titleName = $eachLineOpfTxt;
$titleName =~ s@^.*?<dc:title[^>]*?>【試し読み版】(.*?)<\/dc:title>.*?$@$1@s;
##############コピー元ファイルを展開##############
open(SAMPLEIN,"$pSampleFilePath");
#改行コードの統一処理
@eachLineSampleTxts = <SAMPLEIN>;
$eachLineSampleTxt = join("",@eachLineSampleTxts);
$eachLineSampleTxt =~ s@\x0D\x0A@\x0D@g;
$eachLineSampleTxt =~ s@\x0A@\x0D@g;
@eachLineSampleTxts = split("\x0D",$eachLineSampleTxt);
$eachLineSampleTxt = join("\x0D\x0A",@eachLineSampleTxts);
close (SAMPLEIN);
$eachLineSampleTxt = decode('UTF-8', $eachLineSampleTxt);
#タイトル行を置換
$eachLineSampleTxt =~ s@<title>.*?</title>@<title>$titleName</title>@;
#修正済みファイル出力処理
open(SAMPLEOUT,"> $copySpotPath");
$eachLineSampleTxt = encode('UTF-8', $eachLineSampleTxt);
print SAMPLEOUT $eachLineSampleTxt;
close (SAMPLEOUT);
}
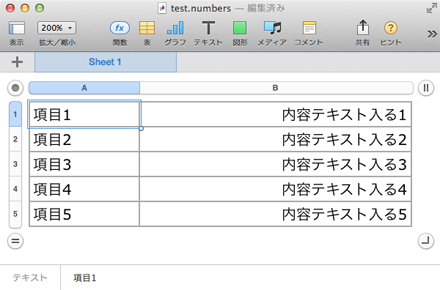 変換元データはこんな感じ。なお今回はPerl側で変換元の文字コードにUTF-8を指定しています。ExcelからCSVを出力した場合はShift_Jisで出力されるようですので、一度テキストエディタで開いて文字コードを変換する必要があります。なお、今回利用したNumbersでは出力時に文字コードを指定できる模様です。
変換元データはこんな感じ。なお今回はPerl側で変換元の文字コードにUTF-8を指定しています。ExcelからCSVを出力した場合はShift_Jisで出力されるようですので、一度テキストエディタで開いて文字コードを変換する必要があります。なお、今回利用したNumbersでは出力時に文字コードを指定できる模様です。