EPUB用IVS/サロゲートペア文字チェッカーを作ってみた
2013/05/07 前回のエントリで書かせていただいた通り、現状IVS/サロゲートペア文字はビューアの表示でトラブルになるケースが多いため、EPUB3データの中にIVS/サロゲートペア文字が混入していないかどうかチェックするためのチェッカーを作ってみました。また、三分スペース(THREE-PER-EM SPACE/U+2004)などのJIS X0213に符号位置割り当てのないスペース文字が一部のリーディングシステムで文字化けするとのお話がありましたので、こちらのチェックもできるようにいたしました(ある方よりご要望をいただいたため機能を追加しました)。
引数としてEPUBファイルのパスを与えてやると内容をチェックしてログを出力するだけの簡単なものですが、制作の役に立てていただければ幸いです。
Mac、Winともに使用することは可能ですが、環境によってはモジュールの追加インストールが必要になるかも知れません。私の環境ではWindowsのActivePerl環境にMinGWモジュールを追加インストールする必要がありました(コマンドプロンプトで「ppm install MinGW」と入力)。
use utf8;
#Encodeモジュールをインポート
use Encode qw/encode decode/;
use File::Basename qw/basename dirname/;
use Archive::Zip;
use Archive::Extract;
use File::Path;
#引数1で指定したepubファイルを取得
$epubFilePath = $ARGV[0];
$epubFilePath = decode(‘UTF-8’, $epubFilePath);
my $epubFileName = basename $epubFilePath;
###################チェック用一時epubファイルのパスを取得###################
my $epubpackage = Archive::Zip->new();
die unless $epubpackage->read($epubFilePath) == Archive::Zip::AZ_OK;
#パスリスト変数の定義
my @xhtmlfilePaths;
my @files = $epubpackage->members();
foreach my $file (@files) {
push(@xhtmlfilePaths,$file->fileName) if ($file->fileName =~ /^(.*?)\.xhtml$/);
}
###################チェック用一時ファイル解凍処理###################
my $uniqueFolderPath = ‘/tmp/’ . $epubFileName;
#同一フォルダが存在したら連番をつける処理
my $mynum = 1;
if (-d $uniqueFolderPath){
while (-d $uniqueFolderPath){
$uniqueFolderPath = (‘/tmp/’ . $epubFileName . ‘_’ . $mynum);
$mynum++;
}
}
#解凍実行
my $epubArchive = Archive::Extract->new(archive => $epubFilePath,type => ‘zip’) or die;
$epubArchive->extract(to => $uniqueFolderPath);
###################文字チェック処理###################
#ログ出力用変数定義
our $finalSarrogatePairOutputLog = “”;
our $finalIVSOutputLog = “”;
our $finalIrregularSpaceOutputLog = “”;
#各xhtmlファイルを展開
foreach $myXhtmlfilePath (@xhtmlfilePaths){
&eachFileProceed($myXhtmlfilePath);
}
###################ログにタイトル部分を合成###################
if ($finalSarrogatePairOutputLog eq “”){
$finalSarrogatePairOutputLog = ‘##SarrogatePair Character Check Result : ‘ . “\r\n” . ‘OK! Not Any SarrogatePair Characters in EPUB File!’;
} else {
$finalSarrogatePairOutputLog = ‘##SarrogatePair Character Check Result : ‘ . “\r\n” . $finalSarrogatePairOutputLog;
}
if ($finalIVSOutputLog eq “”){
$finalIVSOutputLog = ‘##Unicode IVS Character Check Result : ‘ . “\r\n” . ‘OK! Not Any Unicode IVS Characters in EPUB File!’;
} else {
$finalIVSOutputLog = ‘##Unicode IVS Character Check Result : ‘ . “\r\n” . $finalIVSOutputLog;
}
if ($finalIrregularSpaceOutputLog eq “”){
$finalIrregularSpaceOutputLog = ‘##Irregular Space Character Check Result : ‘ . “\r\n” . ‘OK! Not Any Irregular Space Characters in EPUB File!’;
} else {
$finalIrregularSpaceOutputLog = ‘##Irregular Space Character Check Result : ‘ . “\r\n” . $finalIrregularSpaceOutputLog;
}
###################チェック用一時ファイルの削除###################
rmtree($uniqueFolderPath);
###################ログ出力###################
my $logOutputPath = (dirname $epubFilePath) . ‘/EpubTotalDataCheck.log’;
$logOutputPath = encode(‘UTF-8’, $logOutputPath);
open(OUT,”>> $logOutputPath”);
#チェックしたepubファイル名を出力
my $finalFilename = ‘####Checked FileName : ‘ . “\r\n” . $epubFileName;
$finalFilename = encode(‘UTF-8’, $finalFilename);
print OUT $finalFilename . “\r\n\r\n”;
#サロゲートペア文字の有無を出力
$finalSarrogatePairOutputLog = encode(‘UTF-8’, $finalSarrogatePairOutputLog);
print OUT $finalSarrogatePairOutputLog . “\r\n\r\n”;
#Unicode IVS文字の有無を出力
$finalIVSOutputLog = encode(‘UTF-8’, $finalIVSOutputLog);
print OUT $finalIVSOutputLog . “\r\n\r\n”;
#特殊スペース文字の有無を出力
$finalIrregularSpaceOutputLog = encode(‘UTF-8’, $finalIrregularSpaceOutputLog);
print OUT $finalIrregularSpaceOutputLog . “\r\n\r\n”;
close (OUT);
exit;
###################サブルーチン###################
#各xhtmlファイルのチェック
sub eachFileProceed {
my $myXhtmlfilePath = $_[0];
#各xhtmlファイル名を取得
our $xhtmlFileName = basename $myXhtmlfilePath;
my $eachFilePath = ($uniqueFolderPath . “/” . $myXhtmlfilePath);
open(IN,”$eachFilePath”);
#改行コードの統一処理
@myCHECKFILEtxts =
; $myCHECKFILEtxts = join(“”,@myCHECKFILEtxts);
$myCHECKFILEtxts =~ s@\x0D\x0A@\x0D@g;
$myCHECKFILEtxts =~ s@\x0A@\x0D@g;
$myCHECKFILEtxts = decode(‘UTF-8’, $myCHECKFILEtxts);
@eachLine = split(“\x0D”,$myCHECKFILEtxts);
close (IN);
our $lineNumCount = 1;
#各ファイル内各行にIVS/サロゲートペア文字が含まれているかどうかのチェック
foreach $myLine (@eachLine){
&eachLineProceed($myLine);
$lineNumCount++;
}
}
#各xhtmlファイル内各行のチェック
sub eachLineProceed {
my $myLine = $_[0];
###サロゲートペア文字参照のチェック、ログに追記###
#16進数
while($myLine =~ /&\#x2[0-9A-Z]{4};/ig) {
$matchPlace = pos($myLine);
$finalSarrogatePairOutputLog = ($finalSarrogatePairOutputLog . ‘Caution! SarrogatePairCharacterRefernce at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $matchPlace . “\n”)
}
#10進数
while($myLine =~ /&\#(1[0-9]{5});/ig) {
$matchPlace = pos($myLine);
if ($1 >= 131072 && $1 <= 196607) {
$finalSarrogatePairOutputLog = ($finalSarrogatePairOutputLog . ‘Caution! SarrogatePairCharacterRefernce at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $matchPlace . “\n”)
}
}
###IVS文字参照のチェック###
#16進数
while($myLine =~ /&\#xE[0-9A-Z]{4};/ig) {
$matchPlace = pos($myLine);
$finalIVSOutputLog = ($finalIVSOutputLog . ‘Caution! UnicodeIVSCharacterRefernce at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $matchPlace . “\n”)
}
#10進数
while($myLine =~ /&\#(9[0-9]{5});/ig) {
$matchPlace = pos($myLine);
if ($1 >= 917504 && $1 <= 983039) {
$finalIVSOutputLog = ($finalIVSOutputLog . ‘Caution! UnicodeIVSCharacterRefernce at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $matchPlace . “\n”)
}
}
###特殊スペース文字のチェック###
#16進数
while($myLine =~ /&\#x(200[456789ACD]);/ig) {
$matchPlace = pos($myLine);
$finalIrregularSpaceOutputLog = ($finalIrregularSpaceOutputLog . ‘Caution! IrregularSpaceCharactorRefernce at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $matchPlace . “\n”)
}
#10進数
while($myLine =~ /&\#(819[6789]|820[01245]);/ig) {
$matchPlace = pos($myLine);
$finalIrregularSpaceOutputLog = ($finalIrregularSpaceOutputLog . ‘Caution! IrregularSpaceCharactorRefernce at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $matchPlace . “\n”)
}
#キャラクタごとの処理へ
my @eachchara = split(//,$myLine);
our $CharaNumCount = 1;
foreach $mychara(@eachchara){
&eachCharaProceed($myChara);
$CharaNumCount++;
}
}
#各xhtmlファイル内各行内各キャラクタのチェック
sub eachCharaProceed {
my $myChara = $_[0];
###サロゲートペア文字のチェック###
#サロゲートペア文字の場所をチェック、ログに追記
if ($mychara =~ /[\x{20000}-\x{2FFFF}]/){
$finalSarrogatePairOutputLog = ($finalSarrogatePairOutputLog . ‘Caution! SarrogatePairCharacter at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $CharaNumCount . “\n”)
}
###IVS文字のチェック###
#Unicode IVS文字の場所をチェック、ログに追記
if ($mychara =~ /[\x{E0000}-\x{EFFFF}]/){
$finalIVSOutputLog = ($finalIVSOutputLog . ‘Caution! UnicodeIVSCharacter at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $CharaNumCount . “\n”)
}
###特殊スペース文字のチェック###
#4分スペースなどの特殊スペース文字が含まれているかどうかのチェック
if ($mychara =~ /[\x{2004}-\x{200A}\x{200C}-\x{200D}]/){
$finalIrregularSpaceOutputLog = ($finalIrregularSpaceOutputLog . ‘Caution! IrregularSpaceCharactor at ‘ . ‘ ‘ . ‘FileName:’ . $xhtmlFileName . ‘ ‘ . ‘Line:’ . $lineNumCount . ‘ ‘ . ‘Character:’ . $CharaNumCount . “\n”)
}
}
なお、Mac用にはEPUBCheck 3.0を組み込み、同時にログ出力できるようにしたドロップレットを作ってみました。Mac OS X 10.6/10.7/10.8で動作を確認しています。Mac OS X 10.5でも動作自体はしたのですが、Perlの呼び出しでエラーが出ました。Perlのアップデートが必要になると思われます。
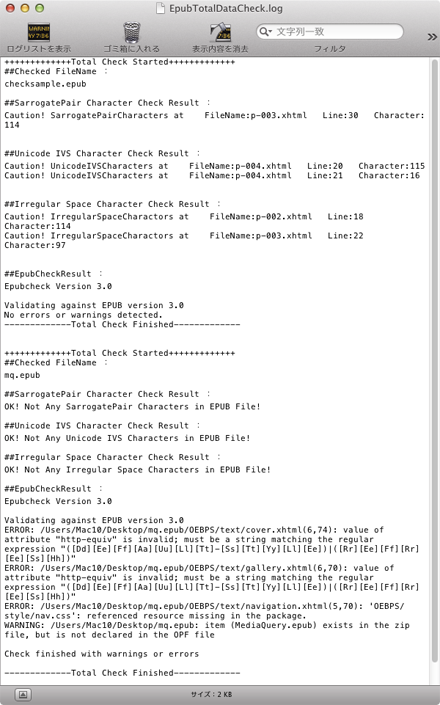
実行ログ
Mac版ドロップレットはIVS/サロゲートペア文字のチェックとEPUBCheckを連続実行しますので、多数のepubファイルをまとめてチェックすると多少の時間がかかります。チェック結果は、epubファイルと同じ場所に出力される「EpubTotalDataCheck.log」で一括確認できます。既に同名のファイルが存在していた場合は末尾に追記します。
チェック完了時にアラートを表示
なお、こちらのスクリプトを使用したことにより生じた損害等につきましては、一切責任を負いかねますので、あくまで自己責任にてご使用ください。
ドロップレットのダウンロードはこちらからどうぞ。
>>EPUB3トータルデータチェッカー2.1.0(Mac用アプリ) ダウンロードはこちら
>>EPUB内特殊文字チェックスクリプト&バッチファイル(Win用) ダウンロードはこちら
なお、Windowsでは、事前にActiveperl等のperl環境のインストールが必要です。
(2013.5.07)
ご要望をいただき、ログファイルにチェックした日付・時刻を出力する機能を追加いたしました。
(2013.5.09追記)
「電書ちゃんねる」に、epubcheckに関する記事が掲載されたようです。「エラーメッセージ一覧日本語訳」はとても参考になるありがたい資料ですのでぜひ参照することをおすすめします。
(2013.5.23追記)
数値文字参照形式でドキュメント内に挿入されたIVS/サロゲートペア文字、特殊幅スペース文字のチェックに対応させる形でソースコードを修正しました。また、Mac用アプリにつきましては「EPUB3トータルデータチェッカー1.1」にてEpubCheck3.0.1にも対応させました。
(2013.5.29追記)
特殊幅スペース文字として「|」(U+007C)が検出されていた問題を修正しました。ダウンロードコンテンツも同様に修正済みです。
(2013.6.04追記)
 」(20BB7)
」(20BB7) 」(29FCE)が表示出来ていないこと、Windows版でIVS文字の「
」(29FCE)が表示出来ていないこと、Windows版でIVS文字の「 」(242EE E0101)が化けていることを除けば、かなり理想的な対応状況です。「
」(242EE E0101)が化けていることを除けば、かなり理想的な対応状況です。「 」(2000B)などいくつかの文字が化けますが、これはフォントに字形が収録されていないためでしょう。
」(2000B)などいくつかの文字が化けますが、これはフォントに字形が収録されていないためでしょう。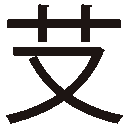 」(26AFF)および「
」(26AFF)および「 」(237FF)以外はきちんと表示されています。この2文字につきましては、おそらくフォント側に字形がないために表示できていないものと思われます。
」(237FF)以外はきちんと表示されています。この2文字につきましては、おそらくフォント側に字形がないために表示できていないものと思われます。
 」(2A61A)が化けるのですが、これはフォントに収録されている字形数の差によるものと思います。
」(2A61A)が化けるのですが、これはフォントに収録されている字形数の差によるものと思います。
 」(200A2)や「
」(200A2)や「 」(200A4)が横転表示されてしまいました。使用頻度の高い文字はほぼ無いのですが、該当する文字を使用する場合にはCSSで正立を指示する必要がありそうです。
」(200A4)が横転表示されてしまいました。使用頻度の高い文字はほぼ無いのですが、該当する文字を使用する場合にはCSSで正立を指示する必要がありそうです。
")
")
")
")
")
")
