2017/08/04
こちらのエントリは、JAGAT XMLパブリッシング準研究会で今期の研究テーマとして、W3C文書「日本語組版処理の要件」(JLREQ)と、これに関連してVivliostyleの村上真雄さんたちが提出したW3Cメンバーサブミッション「Web技術を用いた日本語組版の現状」を取り扱っていることに伴い、会員以外の方の意見を広く求めるとともに、記録を残しておく目的で議事録をベースに補足したものを公開するものです。
間違い、補足などございましたらご意見いただければ幸いです。なお、当ブログはコメント許可制を取っているため、反映に時間がかかります。あらかじめご理解ください。
方針としましてはW3C文書「日本語組版処理の要件」(JLREQ)を先頭から読んでいき、各要素に対応するCSSが存在するのか、存在するとして実用段階なのか、InDesignなどの組版ソフトではどういった形で機能を実現しているのか(いないのか)、などについて見ています。なお全体に対しての包括的な説明の部分に関しては、細かな部分は次回以降にその部分の説明が出てきた時に掘り下げる、としてスルーしている箇所があります。
なお、こちらで取り上げております各CSSプロパティはまだドラフト仕様の段階のものも多いため、今現在すぐに使えるものばかりではありません。Webブラウザで使用出来るかどうかはこちらなどでご確認ください。また、電子書籍のRSで使用出来るかどうかは、現在広範に調査した資料がありません。いずれ当研究会の活動として調査を行いたく考えていますが、しばらく時間はかかるかと思います。
例えば『」「』(閉じカギと開きカギが連続する場合)の間のスペースは前の文字に付くスペースなのか後ろの文字に付くスペースなのか。どちらに付くのかで例えば文字を拡大したときの挙動が変わる。
これに対して次のような意見が出た。
「どちらにつくものでもないので、(CSSの規格やRSの実装としては)前後の文字を二分モノと考えて、適宜スペースを挿入するという考え方もありではないか(小林さん)。」
「適宜スペースを挿入してゆくとどこまでも字間が開いてしまうので、最大値を定めるのもありかもしれない(木枝さん)。」
私個人の意見としては、現状「版面(というべきかどうか)のサイズを本文文字サイズの整数倍にする」というベタ組みの基本ルールが規格化されていないわけで、それを抜きにして個々の箇所のツメを厳密に決めてもほとんど意味がないと思っている。もし今後も当面ベタ組みの規格化が望めないのであれば、小林さんの案のようにスペースをある程度フレキシブルに伸縮できるものとするのがよいのではないか。その上で木枝さんの話のようにスペースによる調整量にリミットを設け、リミットを超過した場合には文字間を割って調整する形にするのがよさそう。
「文末にくる区切り約物(疑問符・感嘆符)の前はベタ組とし,区切り約物の後ろは全角アキとする(図73).ただし,区切り約物の後ろに終わり括弧類がくる場合は,この字間はベタ組とし,終わり括弧類の後ろを二分アキにする」
!?の後のスペースが行頭に送られて字下げにならないように全角スペースのぶら下がりを許容するべきではないか、という意見が出ていた。
JLREQ本文には「終わり括弧類,ハイフン類,区切り約物,中点類,句点類,読点類,繰返し記号,長音記号,小書きの仮名及び割注終わり括弧類を行頭に配置してはならない(行頭禁則).これは体裁がよくないからである.」とあるが、注の表記内でさまざまなバリエーションを記述してある模様。
※ベタ組みの横のラインの保持を優先し、長音記号や小書きの仮名の行頭配置を許容する考え方もあるよう。これは歴史のある出版社に多く見られるルールのようだ。
CSS:禁則
CSS Text Module Level 3 5.3. Line Breaking Rules: the line-break property
禁則に関しての規定。autoでは本来は一行文字数に応じて徐々に緩い禁則になる実装が期待されるが、実際にはあまりそういった実装はされておらず、Normalとほぼ同義になっているものと思われる。
「行末に配置する終わり括弧類(cl-02),読点類(cl-07)及び句点類(cl-06)は,その後ろを原則として二分アキとする(図76 ).」
「(活字組版時代は,次の考え方が主流であった(図78 ).として)行長に過不足が発生し,行の調整処理で詰める処理の必要がある場合(3.8 行の調整処理を参照),優先的に句点類,読点類及び終わり括弧類の後ろの二分アキをベタ組にする.これは,行末でもあり,これらの後ろの二分アキがベタ組になってもほとんど問題にならないからである.なお,この二分アキを中間的な四分アキにするという方法は採用されていなかった.二分アキ又はベタ組のいずれかを選択する,ということである.また,行の調整処理で詰める処理が必要な場合,句点類,読点類及び終わり括弧類の後ろの二分アキより優先順位は低くなるが,中点類の前後の四分アキをベタ組にする.」
※「そもそも活字の時代には全角の中黒しかなかった」とのこと。必要に応じて削っていたそう。そういった対処が必要だったことが、ツメ処理の優先順位で中点類がカギ類などより後になっていることに影響しているのではないか。
※JLREQはあくまで活版ペースでの記述なので、長体平体の記述はない。おそらく写植起源のため。
「DTPなどでは,行末に配置する句点類,読点類及び終わり括弧類のすべての後ろをベタ組とする処理法も行われている(図79 ).」
これに対応するCSS指定がtext-spacingの「trim-end」。なお、「no-compress」という指定もあるが、これは後日JLREQ 3.8.2に関連して触れる予定なのでここでは深掘りしない。
「次のような文字・記号が連続する場合は,その字間で2行に分割しない(分割禁止).これは,それらの文字・記号を一体として扱いたいためである.」
※分離禁止とは違う用語なので注意。
JLREQでは二倍ダーシ、三点リーダ、アラビア数字の字間などの例が挙げられている。
※UnicodeでTWO-EM DASHという符合位置が規定されたのに対応して、2倍ダーシを独自グリフとして持っているフォントも出てきている(源ノ角ゴシックなど)。これは活版のグリフの再現と見ることもできそう。なお符合位置としてはTHREE-EM DASHも既にあるようだ。
※図84の123 4 のアキは位取りとのことだがほとんど見たことがない。用例はどのあたりだろうか? また、ちょっとわかりにくく、誤植を疑ってしまったのでもう少し桁数を増やして欲しい。
CSS:分割禁止/許容
CSS Text Module Level 3 5.3. Breaking Rules for Letters: the ‘word-break’ property
・word-break:normal
一般的なルールに従って単語を分断する
・word-break:keep-all
単語の中での分断は禁止される。CJKの文字(漢字、かな、カナを含む)は分割されなくなる。
・word-break:break-all
normalでの分断可能部分に加えて、単語の中での分断も許容される。
今回はここまで。次回はJLREQ 3.1.10のgから。
(2017.8.7)
CSS Text Module Level 3のリンク参照先を10 August 2017のワーキングドラフトに変更しました。
(2017.9.4更新)
タグ: CSS, JAGAT, JLREQ, W3C, Web技術を用いた日本語組版の現状, 日本語組版, 日本語組版処理の要件
カテゴリー: 未分類 | 2 件のコメント »
2017/07/27
PerlのXMLパーサーモジュール、XML::LibXMLで文字コードShift_JISのXMLをパースしようとしてしばらくハマったので将来の自分用にメモを残しておきます。
$doc = $parser->parse_file(〜)でエラー
XML::LibXMLは$doc = $parser->parse_file(〜)の書式で外部XMLファイルのパスを指定して直接読み込めるのですが、どうもうまくいきません。
用意した読み込み元のXMLは次のような感じ。
|
|
<?xml version="1.0" encoding="Shift_JIS"?> <TEST> <CONTENTS> <PARAGRAPH>吾輩は猫である。名前はまだ無い。</PARAGRAPH> <PARAGRAPH>どこで生れたかとんと見当がつかぬ。</PARAGRAPH> <PARAGRAPH>何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。</PARAGRAPH> <PARAGRAPH>吾輩はここで始めて人間というものを見た。</PARAGRAPH> <PARAGRAPH>しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。</PARAGRAPH> </CONTENTS> </TEST> |
これを以下のコードでパースしようとして
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
#!/usr/bin/perl use utf8; use warnings; use XML::LibXML; use Encode qw/encode decode/; #変換するXMLファイルのパスを取得 my $convertXmlFilePath = $ARGV[0]; $convertXmlFilePath = decode('UTF-8', $convertXmlFilePath); #ファイルを読み込んでパース my $parser = XML::LibXML->new(); $parser->no_network(1); my $dom = $parser->parse_file($convertXmlFilePath); #<TEST>タグの中身取得 my $tags = $dom->findnodes('///TEST'); #テキスト化して配列収納 my @eachLines; foreach my $tag(@$tags){ push (@eachLines, $tag->serialize); } #テスト出力 my $joinedTxt = join("\x0A",@eachLines); $joinedTxt = encode('UTF-8', $joinedTxt); print $joinedTxt . "\n"; |
以下のようなエラーが返ります。

読み込み元のXMLの文字コード(と宣言文)をUTF-8に変えてやれば普通に読み込めるので、Shift_JIS由来の問題に間違いないようです。どうもXML::LibXMLの$doc = $parser->parse_file(〜)がShift_JISに対応していないのが原因のよう。
$doc = $parser->parse_string(〜)でもエラーになる
困ったなということでネットでいろいろ情報を集めたのですが、use utf8;を宣言していない例とかしか引っかからなくて困りました。Perlの内部コードをShit_JISにしてやりゃそりゃ読めるでしょうが、Unicodeにしかない文字とか扱う可能性があるのでそれじゃダメなのよ。
ということで作戦2として、一旦encodeモジュールを使って内部文字列として読み込んでやり、それを$doc = $parser->parse_string(〜)でパースしてみます。コードは以下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
#!/usr/bin/perl use utf8; use warnings; use XML::LibXML; use Encode qw/encode decode/; #変換するXMLファイルのパスを取得 my $convertXmlFilePath = $ARGV[0]; $convertXmlFilePath = decode('UTF-8', $convertXmlFilePath); #内部文字列として一度展開 open(IN,"$convertXmlFilePath"); @eachLineTxts = <IN>; $xmlTxt = join("",@eachLineTxts); $xmlTxt = decode('Shift_JIS', $xmlTxt); close (IN); #ファイルを読み込んでパース my $parser = XML::LibXML->new(); $parser->no_network(1); my $dom = $parser->parse_string($xmlTxt); #<TEST>タグの中身取得 my $tags = $dom->findnodes('///TEST'); #テキスト化して配列収納 my @eachLines; foreach my $tag(@$tags){ push (@eachLines, $tag->serialize); } #テスト出力 my $joinedTxt = join("\x0A",@eachLines); $joinedTxt = encode('UTF-8', $joinedTxt); print $joinedTxt . "\n"; |
しかしこれでもエラー。

んー・・・
$doc = $parser->読み込んだ文字列内の文字コード宣言の部分を置換して読み込ませて解決
どうしたものかなとしばらくいろいろ($dom = XML::LibXML->load_xml();方面とか)試していたのですがうまくいかず。
もう一度エラー内容とコードを眺めていたら、もしかして読み込みXMLソース内の「encoding="Shift_JIS"」の宣言がイタズラしてるのでは?と思い、一行追加。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
#!/usr/bin/perl use utf8; use warnings; use XML::LibXML; #use XML::LibXML::XPathContext; use Encode qw/encode decode/; #変換するXMLファイルのパスを取得 my $convertXmlFilePath = $ARGV[0]; $convertXmlFilePath = decode('UTF-8', $convertXmlFilePath); #内部文字列として一度展開 open(IN,"$convertXmlFilePath"); @eachLineTxts = <IN>; $xmlTxt = join("",@eachLineTxts); $xmlTxt = decode('Shift_JIS', $xmlTxt); close (IN); #エンコーディング宣言の部分を置換(↓この行を追記) $xmlTxt =~ s@encoding=\"Shift_JIS\"@encoding=\"UTF-8\"@; #ファイルを読み込んでパース my $parser = XML::LibXML->new(); $parser->no_network(1); my $dom = $parser->parse_string($xmlTxt); #<TEST>タグの中身取得 my $tags = $dom->findnodes('///TEST'); #テキスト化して配列収納 my @eachLines; foreach my $tag(@$tags){ push (@eachLines, $tag->serialize); } #テスト出力 my $joinedTxt = join("\x0A",@eachLines); $joinedTxt = encode('UTF-8', $joinedTxt); print $joinedTxt . "\n"; |
これでうまくパースできました。

◇
いやあ文字コードって本当に面倒ですね。
(2017.7.27)
タグ: Perl, Shift_JIS, XML, XML::LibXML, パース
カテゴリー: 未分類 | コメントはまだありません »
2017/07/18
XojoでドロップレットのUIを作る必要があって調べたので備忘録として記しておきます。そのうちまた必要になりそうだし。なおMacで作ってます。Winでどうなのかはテストしてないのでわからないけど流れは多分ほぼ同じ。
アプリアイコンへのドラッグアンドドロップ
アプリアイコンへのドラッグアンドドロップのやり方は以下。
1 ファイルタイプグループを作成
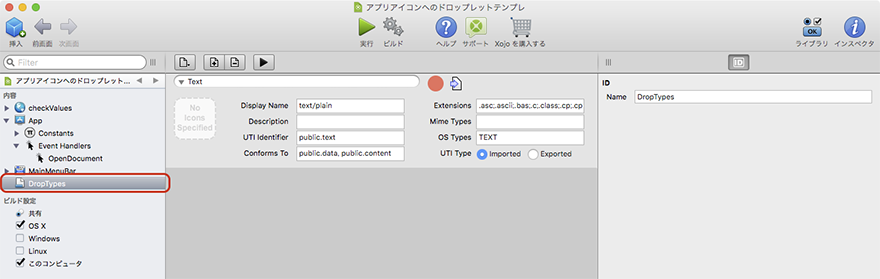 新規にファイルタイプグループを作成し、適宜ドロップしたいファイルタイプを登録する。豊富にファイルタイプのバリエーションが用意されているのでその中から選ぶ感じ。なければ作る。
新規にファイルタイプグループを作成し、適宜ドロップしたいファイルタイプを登録する。豊富にファイルタイプのバリエーションが用意されているのでその中から選ぶ感じ。なければ作る。
2 ビルド設定でドロップできるようにするファイルタイプを選択
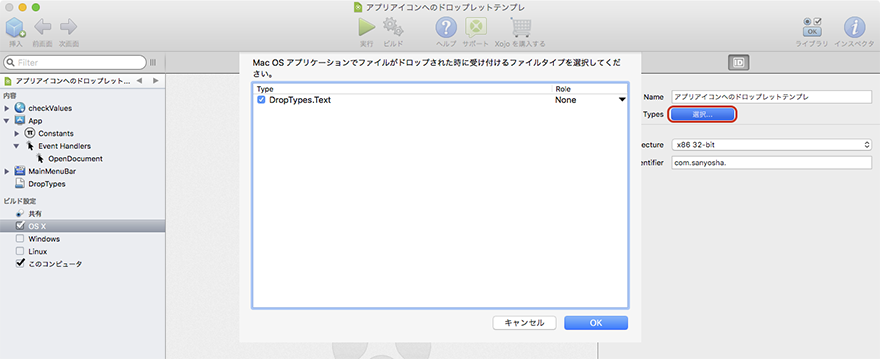 ビルド設定でドロップできるようにするファイルタイプを選択する。1で適切にファイルタイプを設定していれば選択できるようになっているはず。
ビルド設定でドロップできるようにするファイルタイプを選択する。1で適切にファイルタイプを設定していれば選択できるようになっているはず。
3 Appのイベントハンドラ種別でOpenDocumentを選んでコードを記述
AppのイベントハンドラでOpenDocumentを選んで実行したいコードを書く。例えば以下のような感じ。例では拡張子が.TXT以外のものをハネるようにチェックを入れている。もうちょいスマートな方法がありそうなのだが。
|
|
If item <> Nil And item.exists Then dim path as String = item.NativePath '++++++++++++++TXTファイルかどうかのチェック++++++++++++++ Dim txtOrNotValue As Boolean txtOrNotValue = checkTxtFileOrNotValue(path) if txtOrNotValue then MsgBox path Else Exit End if Else MsgBox(item.name+" doesn't seem to exist") End If quit |
チェック用メソッドは
|
|
Dim txtOrNot As Boolean = True '++++++++++++++TXTファイルかどうかのチェック++++++++++++++ Dim rg as New RegEx Dim myMatch as RegExMatch rg.SearchPattern= "\.txt$" myMatch=rg.search(checkFilePath) if myMatch <> Nil then Return True else Return False End if |
単純に正規表現で拡張子をチェックしてマッチするかどうかでTrue/Falseを返して判定してる感じ。
特定のウィンドウ内領域へのドラッグアンドドロップ
特定のウィンドウ内領域へのドラッグアンドドロップのやり方は以下。
1 ファイルタイプグループを作成
新規にファイルタイプグループを作成し、適宜ドロップしたいファイルタイプを登録する。豊富にファイルタイプのバリエーションが用意されているのでその中から選ぶ感じ。なければ作る。
2 ドラッグ&ドロップの対象にしたいエリアを作る
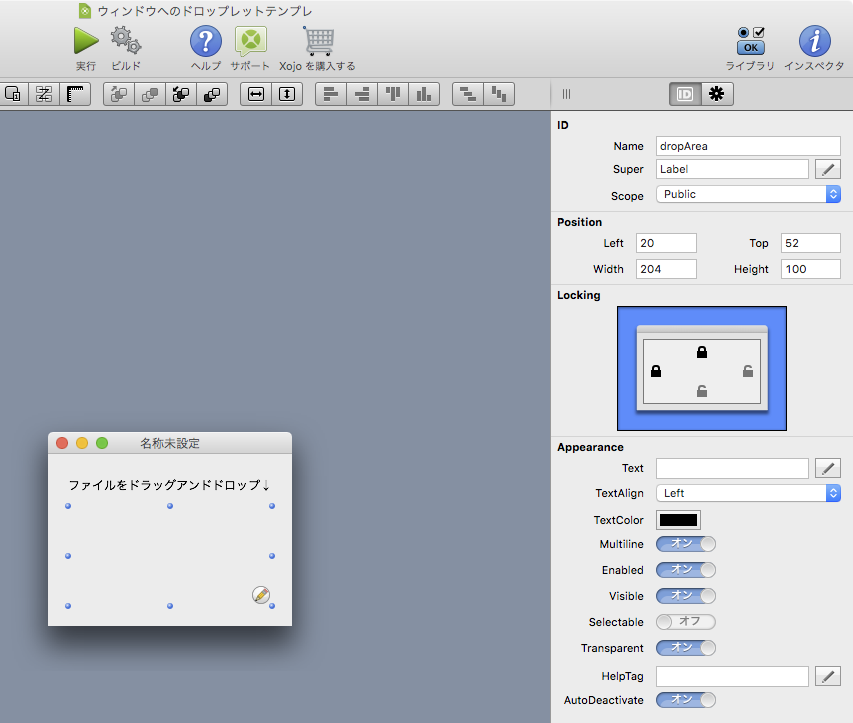 ドラッグ&ドロップの対象にしたいエリアを適宜作る。例ではWindow1の中にdropAreaという領域を設定している。
ドラッグ&ドロップの対象にしたいエリアを適宜作る。例ではWindow1の中にdropAreaという領域を設定している。
3 イベントハンドラ「Open」を設定
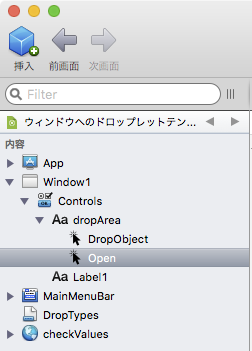 ドラッグ&ドロップの対象エリアにイベントハンドラ「Open」を作り、コードを記述する。コードは以下。
ドラッグ&ドロップの対象エリアにイベントハンドラ「Open」を作り、コードを記述する。コードは以下。
|
|
me.AcceptFileDrop(DropTypes.Text) |
DropTypes.Textの部分は適宜変える。ドロップされるファイルの種別区分をしないならDropTypes.Allとか。
4 イベントハンドラ「DropObject」を設定
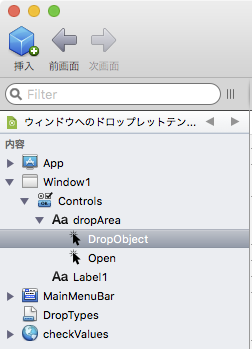 ドラッグ&ドロップの対象エリアにイベントハンドラ「DropObject」を作り、コードを記述する。コードは以下。
ドラッグ&ドロップの対象エリアにイベントハンドラ「DropObject」を作り、コードを記述する。コードは以下。
|
|
if obj.FolderItemAvailable then dim f as FolderItem = obj.FolderItem dim path as String = f.NativePath '++++++++++++++TXTファイルかどうかのチェック++++++++++++++ Dim txtOrNotValue As Boolean txtOrNotValue = checkTxtFileOrNotValue(path) if Not txtOrNotValue then Exit End if If f <> Nil Then dropArea.Text = path End If end |
記述例では拡張子が.TXTかどうかをチェックした上で.TXTだった場合にパスをエリア内に記述している。チェックメソッドのコードは上と同じなので割愛。
複数ファイルをドロップして連続実行させるには「do〜Loop Until Not obj.NextItem」で全体を囲む。
(2017.7.19)
※「RegExはデフォルトで大文字小文字を区別しない」との情報をいただいたのでコードをプチ修正しました。
(2017.7.19追記)
※複数ファイルドロップの場合について追記
(2022.3.4追記)
タグ: Xojo, ドラッグアンドドロップ, ドロップレット
カテゴリー: 未分類 | コメントはまだありません »