濁点のトラブルに遭遇
最近あったちょっとしたトラブルについてちょっとメモ代わりに。epubはおおざっぱに言えばxhtmlをzipで固めたようなものなので、各xhtmlファイルには当然ヘッダ部分があり、タイトルがあるわけなのですが、このタイトル部分に含まれている文字の濁点の部分が「非濁点親文字」 +「゛」の合字になっており、一部のビューアで合字をきちんと表示できないため、問題となりました。以前からFinder内で入力された文字がOS XのUnicode正規化処理によって変換される問題があるという話は知っていたのですが、実際にトラブルに遭遇したのは初めてでした。Unicode正規化処理に関しましてはものかの先生が詳しく解説してますのでこちらの記事を。
OS Xの処理によって濁点が分解される
ざっくり何が起きるのかというと、Finderでファイル名等を入力すると、入力時に例えば「ダ」が「タ」+「゛」に分解されて収納されるということです。商用アプリ等では通常これを見越して再変換処理を行っていると思いますので、そういったアプリだけを利用して仕事を完結させているとこの現象に気づかないケースも多いかと思いますが、自家製スクリプト等でファイル名、フォルダ名などを取得して処理するようなケースではきちんとした対策が必要になってきます。今回はそれをしていなかったために合字が混入してしまいました。
やらなきゃならない処理としては簡単で、変化している可能性のある文字をリスト化して順番に置換をかければいいわけです。ということでものかの先生のサイトで公開されているひらくんさんのperlスクリプトを参考に置換処理を実行。
|
1 2 3 |
use Unicode::Normalize; my $myReg = '[^\x{0340}\x{0341}\x{0343}\x{0344}\x{0374}\x{037E}\x{0387}\x{0958}-\x{095F}\x{09DC}\x{09DD}\x{09DF}\x{0A33}\x{0A36}\x{0A59}-\x{0A5B}\x{0A5E}\x{0B5C}\x{0B5D}\x{0F43}\x{0F4D}\x{0F52}\x{0F57}\x{0F5C}\x{0F69}\x{0F73}\x{0F75}\x{0F76}\x{0F78}\x{0F81}\x{0F93}\x{0F9D}\x{0FA2}\x{0FA7}\x{0FAC}\x{0FB9}\x{1F71}\x{1F73}\x{1F75}\x{1F77}\x{1F79}\x{1F7B}\x{1F7D}\x{1FBB}\x{1FBE}\x{1FC9}\x{1FCB}\x{1FD3}\x{1FDB}\x{1FE3}\x{1FEB}\x{1FEE}\x{1FEF}\x{1FF9}\x{1FFB}\x{1FFD}\x{2000}\x{2001}\x{2126}\x{212A}\x{212B}\x{2329}\x{232A}\x{2ADC}\x{F900}-\x{FA0D}\x{FA10}\x{FA12}\x{FA15}-\x{FA1E}\x{FA20}\x{FA22}\x{FA25}\x{FA26}\x{FA2A}-\x{FA6D}\x{FA70}-\x{FAD9}\x{FB1D}\x{FB1F}\x{FB2A}-\x{FB36}\x{FB38}-\x{FB3C}\x{FB3E}\x{FB40}\x{FB41}\x{FB43}\x{FB44}\x{FB46}-\x{FB4E}\x{1D15E}-\x{1D164}\x{1D1BB}-\x{1D1C0}\x{2F800}-\x{2FA1D}]+'; $xxxx =~ s/($myReg)/NFC($1)/eg; |
これを混入の可能性のある各文字列に対して実行するだけです。
チェッカースクリプトにも処理を追記
ついでに、最終出力EPUBに濁点(U+3099)、半濁点(U+309A)が混入していないかどうかをチェックする処理を以前に作ったスクリプトに追加しました。
ログ出力用変数に
|
1 |
our $finalVoicedSoundmarkOutputLog = ""; |
を追記、
最終出力ログの分岐処理部分に
|
1 2 3 4 5 |
if ($finalVoicedSoundmarkOutputLog eq ""){ $finalVoicedSoundmarkOutputLog = '##Voiced Soundmark Check Result : ' . "\r\n" . 'OK! Not Any Voiced Soundmark in EPUB File!'; } else { $finalVoicedSoundmarkOutputLog = '##Voiced Soundmark Check Result : ' . "\r\n" . $finalVoicedSoundmarkOutputLog; } |
を追記、
ログ出力部に
|
1 2 |
$finalVoicedSoundmarkOutputLog = encode('UTF-8', $finalVoicedSoundmarkOutputLog); print OUT $finalVoicedSoundmarkOutputLog . "\r\n\r\n"; |
を追記、
各キャラクタのチェック用サブルーチン内に
|
1 2 3 |
if ($mychara =~ /[\x{3099}\x{309A}]/){ $finalVoicedSoundmarkOutputLog = ($finalVoicedSoundmarkOutputLog . 'Caution! VoicedSoundmarkCharactors at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $CharaNumCount . "\n") } |
を追記。
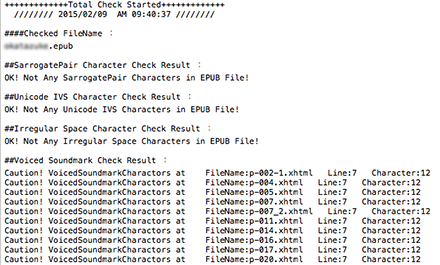 これでEPUBファイル内に濁点(U+3099)、半濁点(U+309A)が混入していた場合にはチェッカーログに出力されるようになりました。
これでEPUBファイル内に濁点(U+3099)、半濁点(U+309A)が混入していた場合にはチェッカーログに出力されるようになりました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 |
use utf8; #Encodeモジュールをインポート use Encode qw/encode decode/; use File::Basename qw/basename dirname/; use Archive::Zip; use Archive::Extract; use File::Path; #引数1で指定したepubファイルを取得 $epubFilePath = $ARGV[0]; $epubFilePath = decode('UTF-8', $epubFilePath); my $epubFileName = basename $epubFilePath; ###################チェック用一時epubファイルのパスを取得################### my $epubpackage = Archive::Zip->new(); die unless $epubpackage->read($epubFilePath) == Archive::Zip::AZ_OK; #パスリスト変数の定義 my @xhtmlfilePaths; my @files = $epubpackage->members(); foreach my $file (@files) { push(@xhtmlfilePaths,$file->fileName) if ($file->fileName =~ /^(.*?)\.xhtml$/); } ###################チェック用一時ファイル解凍処理################### my $uniqueFolderPath = '/tmp/' . $epubFileName; #同一フォルダが存在したら連番をつける処理 my $mynum = 1; if (-d $uniqueFolderPath){ while (-d $uniqueFolderPath){ $uniqueFolderPath = ('/tmp/' . $epubFileName . '_' . $mynum); $mynum++; } } #解凍実行 my $epubArchive = Archive::Extract->new(archive => $epubFilePath,type => 'zip') or die; $epubArchive->extract(to => $uniqueFolderPath); ###################文字チェック処理################### #ログ出力用変数定義 our $finalSarrogatePairOutputLog = ""; our $finalIVSOutputLog = ""; our $finalIrregularSpaceOutputLog = ""; our $finalVoicedSoundmarkOutputLog = ""; #各xhtmlファイルを展開 foreach $myXhtmlfilePath (@xhtmlfilePaths){ &eachFileProceed($myXhtmlfilePath); } ###################ログにタイトル部分を合成################### if ($finalSarrogatePairOutputLog eq ""){ $finalSarrogatePairOutputLog = '##SarrogatePair Character Check Result : ' . "\r\n" . 'OK! Not Any SarrogatePair Characters in EPUB File!'; } else { $finalSarrogatePairOutputLog = '##SarrogatePair Character Check Result : ' . "\r\n" . $finalSarrogatePairOutputLog; } if ($finalIVSOutputLog eq ""){ $finalIVSOutputLog = '##Unicode IVS Character Check Result : ' . "\r\n" . 'OK! Not Any Unicode IVS Characters in EPUB File!'; } else { $finalIVSOutputLog = '##Unicode IVS Character Check Result : ' . "\r\n" . $finalIVSOutputLog; } if ($finalIrregularSpaceOutputLog eq ""){ $finalIrregularSpaceOutputLog = '##Irregular Space Character Check Result : ' . "\r\n" . 'OK! Not Any Irregular Space Characters in EPUB File!'; } else { $finalIrregularSpaceOutputLog = '##Irregular Space Character Check Result : ' . "\r\n" . $finalIrregularSpaceOutputLog; } if ($finalVoicedSoundmarkOutputLog eq ""){ $finalVoicedSoundmarkOutputLog = '##Voiced Soundmark Check Result : ' . "\r\n" . 'OK! Not Any Voiced Soundmark in EPUB File!'; } else { $finalVoicedSoundmarkOutputLog = '##Voiced Soundmark Check Result : ' . "\r\n" . $finalVoicedSoundmarkOutputLog; } ###################チェック用一時ファイルの削除################### rmtree($uniqueFolderPath); ###################ログ出力################### my $logOutputPath = (dirname $epubFilePath) . '/EpubTotalDataCheck.log'; $logOutputPath = encode('UTF-8', $logOutputPath); open(OUT,">> $logOutputPath"); #チェックしたepubファイル名を出力 my $finalFilename = '####Checked FileName : ' . "\r\n" . $epubFileName; $finalFilename = encode('UTF-8', $finalFilename); print OUT $finalFilename . "\r\n\r\n"; #サロゲートペア文字の有無を出力 $finalSarrogatePairOutputLog = encode('UTF-8', $finalSarrogatePairOutputLog); print OUT $finalSarrogatePairOutputLog . "\r\n\r\n"; #Unicode IVS文字の有無を出力 $finalIVSOutputLog = encode('UTF-8', $finalIVSOutputLog); print OUT $finalIVSOutputLog . "\r\n\r\n"; #特殊スペース文字の有無を出力 $finalIrregularSpaceOutputLog = encode('UTF-8', $finalIrregularSpaceOutputLog); print OUT $finalIrregularSpaceOutputLog . "\r\n\r\n"; #濁点半濁点の有無を出力 $finalVoicedSoundmarkOutputLog = encode('UTF-8', $finalVoicedSoundmarkOutputLog); print OUT $finalVoicedSoundmarkOutputLog . "\r\n\r\n"; close (OUT); exit; ###################サブルーチン################### #各xhtmlファイルのチェック sub eachFileProceed { my $myXhtmlfilePath = $_[0]; #各xhtmlファイル名を取得 our $xhtmlFileName = basename $myXhtmlfilePath; my $eachFilePath = ($uniqueFolderPath . "/" . $myXhtmlfilePath); open(IN,"$eachFilePath"); #改行コードの統一処理 @myCHECKFILEtxts = <IN>; $myCHECKFILEtxts = join("",@myCHECKFILEtxts); $myCHECKFILEtxts =~ s@\x0D\x0A@\x0D@g; $myCHECKFILEtxts =~ s@\x0A@\x0D@g; $myCHECKFILEtxts = decode('UTF-8', $myCHECKFILEtxts); @eachLine = split("\x0D",$myCHECKFILEtxts); close (IN); our $lineNumCount = 1; #各ファイル内各行にIVS/サロゲートペア文字が含まれているかどうかのチェック foreach $myLine (@eachLine){ &eachLineProceed($myLine); $lineNumCount++; } } #各xhtmlファイル内各行のチェック sub eachLineProceed { my $myLine = $_[0]; ###サロゲートペア文字参照のチェック、ログに追記### #16進数 while($myLine =~ /&\#x2[0-9A-Z]{4};/ig) { $matchPlace = pos($myLine); $finalSarrogatePairOutputLog = ($finalSarrogatePairOutputLog . 'Caution! SarrogatePairCharacterRefernce at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $matchPlace . "\n") } #10進数 while($myLine =~ /&\#(1[0-9]{5});/ig) { $matchPlace = pos($myLine); if ($1 >= 131072 && $1 <= 196607) { $finalSarrogatePairOutputLog = ($finalSarrogatePairOutputLog . 'Caution! SarrogatePairCharacterRefernce at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $matchPlace . "\n") } } ###IVS文字参照のチェック### #16進数 while($myLine =~ /&\#xE[0-9A-Z]{4};/ig) { $matchPlace = pos($myLine); $finalIVSOutputLog = ($finalIVSOutputLog . 'Caution! UnicodeIVSCharacterRefernce at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $matchPlace . "\n") } #10進数 while($myLine =~ /&\#(9[0-9]{5});/ig) { $matchPlace = pos($myLine); if ($1 >= 917504 && $1 <= 983039) { $finalIVSOutputLog = ($finalIVSOutputLog . 'Caution! UnicodeIVSCharacterRefernce at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $matchPlace . "\n") } } ###特殊スペース文字のチェック### #16進数 while($myLine =~ /&\#x(200[456789ACD]);/ig) { $matchPlace = pos($myLine); $finalIrregularSpaceOutputLog = ($finalIrregularSpaceOutputLog . 'Caution! IrregularSpaceCharactorRefernce at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $matchPlace . "\n") } #10進数 while($myLine =~ /&\#(819[6789]|820[01245]);/ig) { $matchPlace = pos($myLine); $finalIrregularSpaceOutputLog = ($finalIrregularSpaceOutputLog . 'Caution! IrregularSpaceCharactorRefernce at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $matchPlace . "\n") } #キャラクタごとの処理へ my @eachchara = split(//,$myLine); our $CharaNumCount = 1; foreach $mychara(@eachchara){ &eachCharaProceed($myChara); $CharaNumCount++; } } #各xhtmlファイル内各行内各キャラクタのチェック sub eachCharaProceed { my $myChara = $_[0]; ###サロゲートペア文字のチェック### #サロゲートペア文字の場所をチェック、ログに追記 if ($mychara =~ /[\x{20000}-\x{2FFFF}]/){ $finalSarrogatePairOutputLog = ($finalSarrogatePairOutputLog . 'Caution! SarrogatePairCharacters at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $CharaNumCount . "\n") } ###IVS文字のチェック### #Unicode IVS文字の場所をチェック、ログに追記 if ($mychara =~ /[\x{E0000}-\x{EFFFF}]/){ $finalIVSOutputLog = ($finalIVSOutputLog . 'Caution! UnicodeIVSCharacters at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $CharaNumCount . "\n") } ###特殊スペース文字のチェック### #4分スペースなどの特殊スペース文字が含まれているかどうかのチェック if ($mychara =~ /[\x{2004}-\x{200A}\x{200C}-\x{200D}]/){ $finalIrregularSpaceOutputLog = ($finalIrregularSpaceOutputLog . 'Caution! IrregularSpaceCharactors at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $CharaNumCount . "\n") } ###濁点半濁点のチェック### #HFS+の正規化で分解された濁点半濁点が含まれているかどうかのチェック if ($mychara =~ /[\x{3099}\x{309A}]/){ $finalVoicedSoundmarkOutputLog = ($finalVoicedSoundmarkOutputLog . 'Caution! VoicedSoundmarkCharactors at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $CharaNumCount . "\n") } } |
◇
いやまあ今まで経験したことないことがいろいろ起きてきますねえ。刺激はたっぷりあります。今回はものかの先生のお話を聞いておいて本当に助かりました。このお礼はいずれ豆大福などで。
改訂後のMac用ドロップレットです。
>>EPUB3トータルデータチェッカー1.3.0(Mac用アプリ) ダウンロードはこちら
(2015.2.10)
タグ: OS X, Perl, Unicode正規化, 豆大福

2015/04/02 14:02
些末な点ですみませんが、
サロゲートペアって綴りは
“Surrogate Pair”
じゃないでしょうか。
2015/04/02 14:13
おっと、ご指摘ありがとうございます。その通りのようですね。ただ、このエントリ内での英語表記はプログラムコード内のみで使用されているようですので、修正は見送ります。変数名とかですので支障はないだろうということで。次から気をつけます。