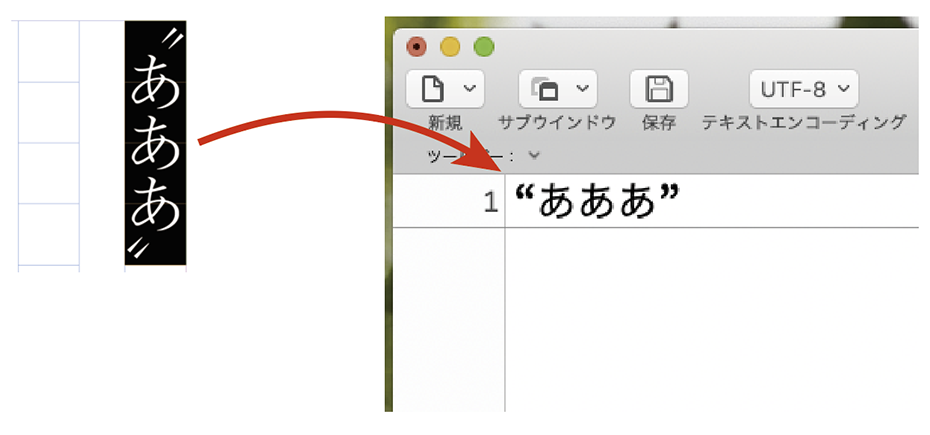
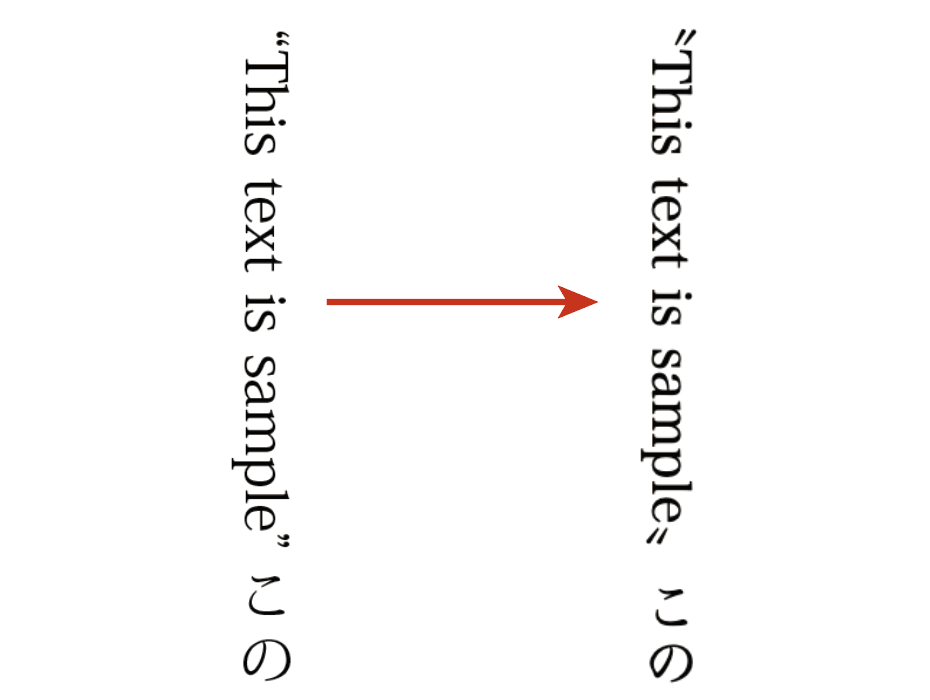
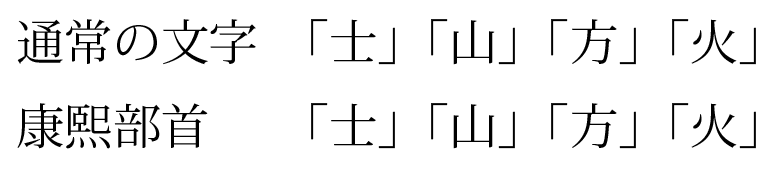テキスト系出版物制作の流れを電子を含めてあらためて最適化できないかと考えています。
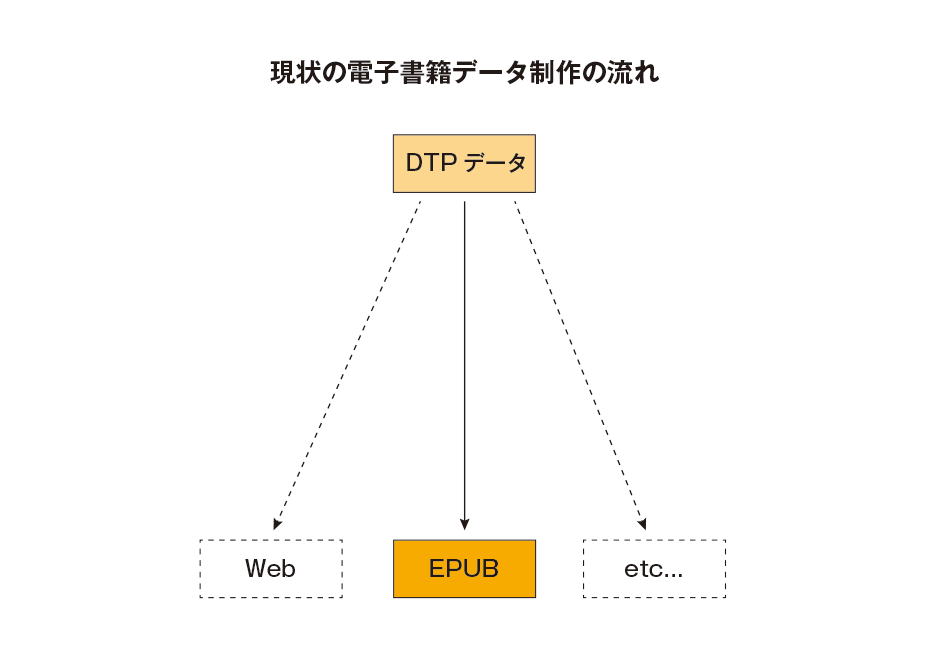 出版社から発売される電子書籍はこれまでほぼ印刷用DTPデータから作られてきました。書籍の制作は実際に本の形に組んでみて、各段階で出力したものに赤字が入り、再校、三校とブラッシュアップされていって最終的に完成に至る、という形で行われるため、完成した状態の最終テキストはDTPデータの中にしか残っていないのが普通です。このため、電子化に際してもDTPデータから注意深くテキストを抜き出す必要がありました。
出版社から発売される電子書籍はこれまでほぼ印刷用DTPデータから作られてきました。書籍の制作は実際に本の形に組んでみて、各段階で出力したものに赤字が入り、再校、三校とブラッシュアップされていって最終的に完成に至る、という形で行われるため、完成した状態の最終テキストはDTPデータの中にしか残っていないのが普通です。このため、電子化に際してもDTPデータから注意深くテキストを抜き出す必要がありました。
ただし、DTPデータを完成させる過程では、(例えば強制改行のような)特殊文字が挿入されたりもしますし、また、組版結果としての見た目は同じでも、オペレーターによって作り方が全然違ったりもします。例えばリストの項目部分だけが別テキストボックスになっているといったようなあまり感心できない作られ方がされているケースも多々あります。このため、電子化に際して自動化による効率化が(InDesign側の作り方に大幅な制限をかけない限り)相当に難しく、結局は個々の本ごとに作業者が判断して多くを手作業によって電子化するというフローにならざるを得ないのが現状です。
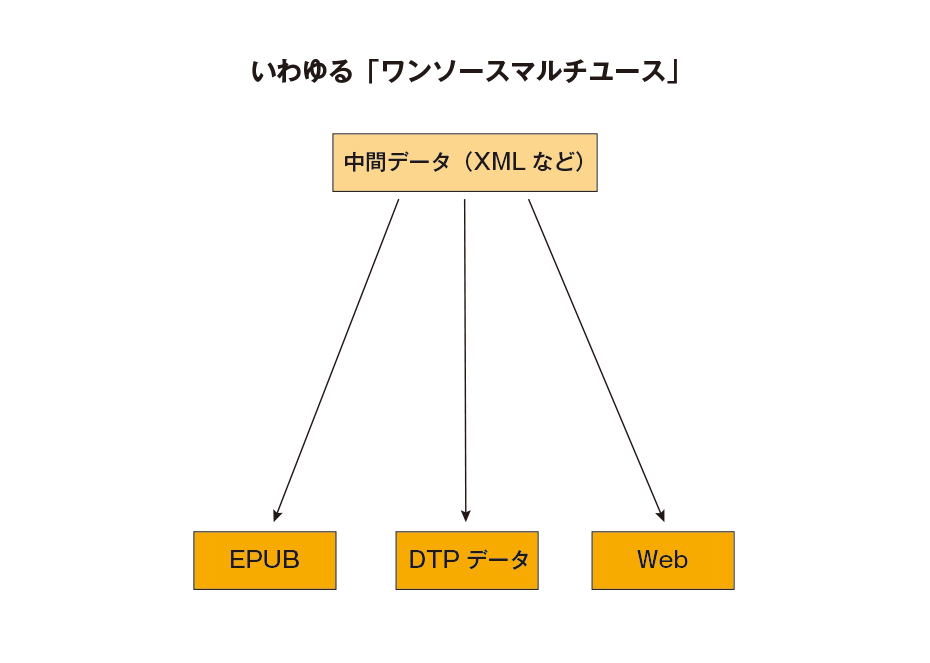 それならば最初にXMLを作ってしまい、そこから各型式に変換して作るのが効率が良い、といういわゆる「ワンソースマルチユース」の考え方もかなり前からありますが、ごく一部を除いて商業出版では普及していないかと思います。1冊ごとに例外処理が発生することが多い出版物制作では結局手作業の方が効率が良かった、スキルを持った作業者の確保が難しかった、成果物を目に見える形にしないと完成度を高めづらい、そもそも求めるレイアウトが固定版面を前提に高度に作り込むものなので構造化が困難、など、それぞれの出版社、制作/印刷会社の事情によって原因はさまざまでしょうから簡単にくくることはできませんが、実際一般に定着していないのは確かです。
それならば最初にXMLを作ってしまい、そこから各型式に変換して作るのが効率が良い、といういわゆる「ワンソースマルチユース」の考え方もかなり前からありますが、ごく一部を除いて商業出版では普及していないかと思います。1冊ごとに例外処理が発生することが多い出版物制作では結局手作業の方が効率が良かった、スキルを持った作業者の確保が難しかった、成果物を目に見える形にしないと完成度を高めづらい、そもそも求めるレイアウトが固定版面を前提に高度に作り込むものなので構造化が困難、など、それぞれの出版社、制作/印刷会社の事情によって原因はさまざまでしょうから簡単にくくることはできませんが、実際一般に定着していないのは確かです。
そういった機械処理を前提とした最適化がされていないままDTPデータから電子版を作ろうとすれば、正直相当大きな手作業の負荷が制作現場にかかるのですが、そういう手間のかかる状況であるにもかかわらず、電子版は紙の本のせいぜい1〜2割の売り上げしか上げられないというのが現状であるため、「電子版は利益にならないから出さない」という判断をしているケースは現状でもかなり多くあるのではないかと思います(最終決定権は著者でしょうが)。おそらく新刊の電子化率が上がっていかない要因のひとつでしょう。
また、電子化するとしても、特に最近はサイマル配信(紙の本とのほぼ同時発売)が求められるため、制作側としてコストや納期の面で苦しさを感じる局面が増えてきました。500ページを超えるような難しめの内容の本を「必ず一週間程度で」電子化する、というのは、実のところかなり大きな負担です。構造化されていない全テキストの構造化および注などのリンク設定、さらには底本と引き合わせての確認作業が入るので当然でしょう。最近よくネットなどで言われている「電子版の発売が紙よりもかなり遅れる」原因はここにもありそうです。これは正直今はまだしも、将来にわたって電子書籍制作の業界が長く持続的に成長していける構造ではないでしょう。
これまでDTPデータから電子版を制作してきたこと、これはまあ仕方がなかったと思います。なにしろ過去に作られた大量のデータがあり、それを電子化することがミッションとされた経緯があるからです。ただ、もし今後も電子書籍と紙の本を同時発売してゆくのならば、おそらくそこは改良の余地があります。そこで、新たな流れをあらためて考えてみました。
最上流としてWebを想定する
最上流にはWebを想定します。これは最近だいぶ出版関係でもWeb運営を事業として安定的に存続している会社が増えてきたことや、noteのようなプロを含む人気の書き手が集まる投稿サービスの定着、「小説家になろう」のようなエンタメ系テキスト投稿サイトの伸張などを念頭に置いたものです。雑誌がどんどん売れなくなっている局面が続いていますので、事前告知のツールとしてのWebは今後ますます重要度を高めてきています。そういう意味でもう最上流にはWebでの告知を考えるのが正しいかなと思っています。いわば雑誌での連載の代わりです。
ただし、本の種類によっては最初にWebに出すことを想定できないことも当然ありますので、ここはいわば「オプション」です。Webで出すことを想定しない場合はこの後からやればよいです。
Webページのデータを元に「先に」EPUBをつくる
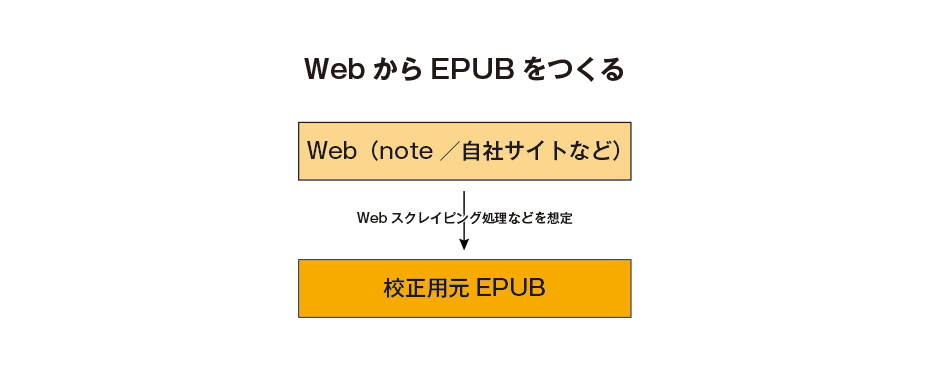 さて、このWebページのデータを元に「先に」EPUBを作ります。もちろんソースをコピーして手作業で書き換えもできるわけですが、可能ならある程度自動化したいところです。WebはHTMLやXHTMLの構造化文書なので、ネットからデータを抽出(スクレイピング)してそこから同じ構造化文書であるEPUBへの変換するのはそれなりに効率化できるはずです。特定のCMSで生成された記事だけを対象とする、などターゲットを絞れるならば、半自動変換まで可能でしょう。現状EPUBでは実質一般のWebよりも使えるCSSが制限されているというような事情はあるため、完全自動変換はかなり難しそうですが。
さて、このWebページのデータを元に「先に」EPUBを作ります。もちろんソースをコピーして手作業で書き換えもできるわけですが、可能ならある程度自動化したいところです。WebはHTMLやXHTMLの構造化文書なので、ネットからデータを抽出(スクレイピング)してそこから同じ構造化文書であるEPUBへの変換するのはそれなりに効率化できるはずです。特定のCMSで生成された記事だけを対象とする、などターゲットを絞れるならば、半自動変換まで可能でしょう。現状EPUBでは実質一般のWebよりも使えるCSSが制限されているというような事情はあるため、完全自動変換はかなり難しそうですが。
気軽に変換ができれば出版企画の検討にも使えると思います。「本として出すか出さないかを検討するためにとりあえず電子書籍の形にしてみる」というイメージです。
EPUBの内容をブラッシュアップして完成させる
 で、一旦形を作ったあと、書籍化に際しての用語統一や約物類などの統一、必要ならコラム類や図表、注の追加など書籍として販売するための追加編集作業を行います。
で、一旦形を作ったあと、書籍化に際しての用語統一や約物類などの統一、必要ならコラム類や図表、注の追加など書籍として販売するための追加編集作業を行います。
ここで問題となるのがEPUBへ修正指示を入れる方法で、EPUBを気軽にプリントする方法がなかったことが長年EPUB制作上の課題ではあったのですが、VivliostyleでEPUBを気軽にPDF化できるようになりましたのでそこはもうクリアです(参考)。
Webを起点としない場合は、テキスト等を元としてEPUBを作ることになりますが、その場合でも作業としては少なくともInDesignを元にするよりは楽なはずです。組版調整のために入れられた電子版では不要な要素を目視確認して取り除く、というような作業はいりませんので。
ただし、ここには一点できれば解決したい技術的な課題があります。それは、現状、電書協ガイド準拠などの商用EPUBの再編集、特に画像や新規挿入やテキストの新規ファイル追加を行う際に気軽に利用できるツールがなく、手動でOPFファイルを編集する必要があることです(manifest追記などを行わないとエラーになる)。その状態だと修正作業を行える人間が限られるため、気軽に再編集ができるツールはあるとよいなと思います。
EPUBからDTP組版用の構造化テキストを変換出力する
 さて、EPUBデータが完成したらそのテキストを元にDTPデータを作成するわけですが、正直この部分での「完全自動組版」などは想定していません。もちろんフローの最適化、効率化は必要ですが、一般的に商業出版のレベルで求められる成果物はテキストから自動変換で作れるようなものではないと思っています。
さて、EPUBデータが完成したらそのテキストを元にDTPデータを作成するわけですが、正直この部分での「完全自動組版」などは想定していません。もちろんフローの最適化、効率化は必要ですが、一般的に商業出版のレベルで求められる成果物はテキストから自動変換で作れるようなものではないと思っています。
従って、ここでは「EPUBから綺麗な形でInDesin等に流し込める構造化テキストを変換出力する」ことを考えます。ルビと見出しぐらいまでを移行できればよい、後は従来のDTP制作と同じ流れに持って行く、という感じです。
この目的のためにはAdobe InCopyの保存形式である「ICML」型式が使えそうかなと思っています(ある程度はテスト済みです)。InCopyはInDesignと組み合わせてレイアウトデザインワークとテキスト修正を同時に別の人間がやるために作られたアプリですが、そのための保存形式である「ICML」型式は内部的にXMLなのでEPUB内のXHTMLからの変換が正規表現の力業に頼らずにできます。
制作イメージとしてはあらかじめInDesignのドキュメント内に流し込むためのボックスを作っておき、そこに変換済みのICMLファイルを配置する感じになり、InDesignタグテキストと変わりません。配置直後はInDesign側に編集権限がないため、「埋め込み」の操作をする必要があるのですが、まあそれだけです。
これだとDTP制作に際して大してメリットがないかのように見えるかもしれませんが、「既に電子版で完成まで行っている」というあたりがポイントになります。つまり、テキストがほぼ完成原稿であり、再校時以降でテキストレベルでの大きな修正が入らないことになります。現状DTP制作では「そうなっていない」ケースが多々あるため、これは実はずいぶん大きな話です。言い換えれば、「テキスト原稿のブラッシュアップのためにEPUBを使う」という話でもあります。
どういうメリットがあるか
このフローに切り替えた場合、各セクションにどういうメリットがあるかをあらためて挙げてみます。
まず、出版社にとってですが、
- 最上流にウェブを置くことで従来の雑誌連載の代わりとして事前告知の効果を期待できる(必ずしも自社で全てやる必要はない)
- EPUBから変換生成されたPDFに赤字を入れて返送という形になるため、従来の本の制作フローの延長として対応できる(その後のDTPでの流れも従来と同じ)
- 制作の流れの中でリフロー型EPUBができるため、DTPデータから改めて短期間でEPUBを作成する必要がなく、出版全体のスケジュールに無理がない(確実にサイマル配信ができる)
- リフロー電子版を紙版と同じように作り込む感覚に引っ張られずに済む(本来それは求められていないはず)
というあたりが思いつきます。特に、従来の本の制作フローから大きく変える必要がないあたりはポイントになりそうです。
電子版の制作会社にとっては、
- ウェブからEPUBへの変換なら構造化文書同士のコンバートになるため、かなりの部分を自動化で対応でき、手作業の手間を減らせる
- 電子版を紙版と同じように作り込むという本来技術的に無理のある作業からの解放
- DTPデータが完成してからごく短時間で電子化、というスケジュールがマストではなくなる
というあたりがメリットになりそうです。
DTP制作会社/印刷会社にとっては
- 「大幅な赤字の入らないほぼ完成した原稿」からDTPデータ作成作業を始められる
- ルビや見出しのレベルまでは無理なくEPUBから持って行ける(それ以上の対応はEPUB側の最適化が必要)
- DTPが制作フローの末端になるため、データの再利用を考えずに作り込むことができる
というあたりでしょうか。
どういう課題がありそうか
一方で、実際にやるにあたっての課題も結構ありそうです。
まず、既に挙げましたが、EPUBの修正作業は現状技術的な敷居が高いため、広くやるためには何らかのツールの開発はいるでしょう。とは言えWYSIWYGで修正できるようにするなどという話でもなければそこまでの手間ではなさそうかなと思います。
また、出版社側を含めて全体の流れの理解はやはり必要と思います。電子版でテキストを完成状態に持って行くという流れが理解されておらず、DTPの段階で大幅な修正が入った場合、手間が大きく増えてフローが破綻しますので。
さらに、ここには図表制作の話は入っていません。電子版でも図表は当然必要になるので、事前に図表制作は進めておく必要があるでしょう。DTPデータでは使える色の制限も当然出てくるため、電子版とDTP用で色を変える対応も必要になってくるかもしれません。
以上になります。あくまで大雑把な流れの提案なので、個々のケースではまた違った話は出てくるかとは思います。
(2020.2.25)