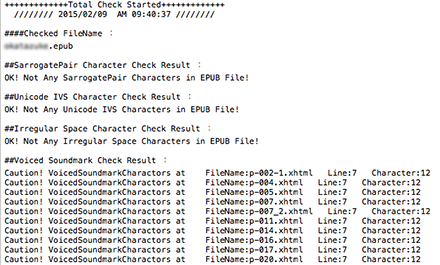
use utf8;
#Encodeモジュールをインポート
use Encode qw/encode decode/;
use File::Basename qw/basename dirname/;
use Archive::Zip;
use Archive::Extract;
use File::Path;
#引数1で指定したepubファイルを取得
$epubFilePath = $ARGV[0];
$epubFilePath = decode('UTF-8', $epubFilePath);
my $epubFileName = basename $epubFilePath;
###################チェック用一時epubファイルのパスを取得###################
my $epubpackage = Archive::Zip->new();
die unless $epubpackage->read($epubFilePath) == Archive::Zip::AZ_OK;
#パスリスト変数の定義
my @xhtmlfilePaths;
my @files = $epubpackage->members();
foreach my $file (@files) {
push(@xhtmlfilePaths,$file->fileName) if ($file->fileName =~ /^(.*?)\.xhtml$/);
}
###################チェック用一時ファイル解凍処理###################
my $uniqueFolderPath = '/tmp/' . $epubFileName;
#同一フォルダが存在したら連番をつける処理
my $mynum = 1;
if (-d $uniqueFolderPath){
while (-d $uniqueFolderPath){
$uniqueFolderPath = ('/tmp/' . $epubFileName . '_' . $mynum);
$mynum++;
}
}
#解凍実行
my $epubArchive = Archive::Extract->new(archive => $epubFilePath,type => 'zip') or die;
$epubArchive->extract(to => $uniqueFolderPath);
###################文字チェック処理###################
#ログ出力用変数定義
our $finalSarrogatePairOutputLog = "";
our $finalIVSOutputLog = "";
our $finalIrregularSpaceOutputLog = "";
our $finalVoicedSoundmarkOutputLog = "";
#各xhtmlファイルを展開
foreach $myXhtmlfilePath (@xhtmlfilePaths){
&eachFileProceed($myXhtmlfilePath);
}
###################ログにタイトル部分を合成###################
if ($finalSarrogatePairOutputLog eq ""){
$finalSarrogatePairOutputLog = '##SarrogatePair Character Check Result : ' . "\r\n" . 'OK! Not Any SarrogatePair Characters in EPUB File!';
} else {
$finalSarrogatePairOutputLog = '##SarrogatePair Character Check Result : ' . "\r\n" . $finalSarrogatePairOutputLog;
}
if ($finalIVSOutputLog eq ""){
$finalIVSOutputLog = '##Unicode IVS Character Check Result : ' . "\r\n" . 'OK! Not Any Unicode IVS Characters in EPUB File!';
} else {
$finalIVSOutputLog = '##Unicode IVS Character Check Result : ' . "\r\n" . $finalIVSOutputLog;
}
if ($finalIrregularSpaceOutputLog eq ""){
$finalIrregularSpaceOutputLog = '##Irregular Space Character Check Result : ' . "\r\n" . 'OK! Not Any Irregular Space Characters in EPUB File!';
} else {
$finalIrregularSpaceOutputLog = '##Irregular Space Character Check Result : ' . "\r\n" . $finalIrregularSpaceOutputLog;
}
if ($finalVoicedSoundmarkOutputLog eq ""){
$finalVoicedSoundmarkOutputLog = '##Voiced Soundmark Check Result : ' . "\r\n" . 'OK! Not Any Voiced Soundmark in EPUB File!';
} else {
$finalVoicedSoundmarkOutputLog = '##Voiced Soundmark Check Result : ' . "\r\n" . $finalVoicedSoundmarkOutputLog;
}
###################チェック用一時ファイルの削除###################
rmtree($uniqueFolderPath);
###################ログ出力###################
my $logOutputPath = (dirname $epubFilePath) . '/EpubTotalDataCheck.log';
$logOutputPath = encode('UTF-8', $logOutputPath);
open(OUT,">> $logOutputPath");
#チェックしたepubファイル名を出力
my $finalFilename = '####Checked FileName : ' . "\r\n" . $epubFileName;
$finalFilename = encode('UTF-8', $finalFilename);
print OUT $finalFilename . "\r\n\r\n";
#サロゲートペア文字の有無を出力
$finalSarrogatePairOutputLog = encode('UTF-8', $finalSarrogatePairOutputLog);
print OUT $finalSarrogatePairOutputLog . "\r\n\r\n";
#Unicode IVS文字の有無を出力
$finalIVSOutputLog = encode('UTF-8', $finalIVSOutputLog);
print OUT $finalIVSOutputLog . "\r\n\r\n";
#特殊スペース文字の有無を出力
$finalIrregularSpaceOutputLog = encode('UTF-8', $finalIrregularSpaceOutputLog);
print OUT $finalIrregularSpaceOutputLog . "\r\n\r\n";
#濁点半濁点の有無を出力
$finalVoicedSoundmarkOutputLog = encode('UTF-8', $finalVoicedSoundmarkOutputLog);
print OUT $finalVoicedSoundmarkOutputLog . "\r\n\r\n";
close (OUT);
exit;
###################サブルーチン###################
#各xhtmlファイルのチェック
sub eachFileProceed {
my $myXhtmlfilePath = $_[0];
#各xhtmlファイル名を取得
our $xhtmlFileName = basename $myXhtmlfilePath;
my $eachFilePath = ($uniqueFolderPath . "/" . $myXhtmlfilePath);
open(IN,"$eachFilePath");
#改行コードの統一処理
@myCHECKFILEtxts = <IN>;
$myCHECKFILEtxts = join("",@myCHECKFILEtxts);
$myCHECKFILEtxts =~ s@\x0D\x0A@\x0D@g;
$myCHECKFILEtxts =~ s@\x0A@\x0D@g;
$myCHECKFILEtxts = decode('UTF-8', $myCHECKFILEtxts);
@eachLine = split("\x0D",$myCHECKFILEtxts);
close (IN);
our $lineNumCount = 1;
#各ファイル内各行にIVS/サロゲートペア文字が含まれているかどうかのチェック
foreach $myLine (@eachLine){
&eachLineProceed($myLine);
$lineNumCount++;
}
}
#各xhtmlファイル内各行のチェック
sub eachLineProceed {
my $myLine = $_[0];
###サロゲートペア文字参照のチェック、ログに追記###
#16進数
while($myLine =~ /&\#x2[0-9A-Z]{4};/ig) {
$matchPlace = pos($myLine);
$finalSarrogatePairOutputLog = ($finalSarrogatePairOutputLog . 'Caution! SarrogatePairCharacterRefernce at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $matchPlace . "\n")
}
#10進数
while($myLine =~ /&\#(1[0-9]{5});/ig) {
$matchPlace = pos($myLine);
if ($1 >= 131072 && $1 <= 196607) {
$finalSarrogatePairOutputLog = ($finalSarrogatePairOutputLog . 'Caution! SarrogatePairCharacterRefernce at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $matchPlace . "\n")
}
}
###IVS文字参照のチェック###
#16進数
while($myLine =~ /&\#xE[0-9A-Z]{4};/ig) {
$matchPlace = pos($myLine);
$finalIVSOutputLog = ($finalIVSOutputLog . 'Caution! UnicodeIVSCharacterRefernce at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $matchPlace . "\n")
}
#10進数
while($myLine =~ /&\#(9[0-9]{5});/ig) {
$matchPlace = pos($myLine);
if ($1 >= 917504 && $1 <= 983039) {
$finalIVSOutputLog = ($finalIVSOutputLog . 'Caution! UnicodeIVSCharacterRefernce at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $matchPlace . "\n")
}
}
###特殊スペース文字のチェック###
#16進数
while($myLine =~ /&\#x(200[456789ACD]);/ig) {
$matchPlace = pos($myLine);
$finalIrregularSpaceOutputLog = ($finalIrregularSpaceOutputLog . 'Caution! IrregularSpaceCharactorRefernce at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $matchPlace . "\n")
}
#10進数
while($myLine =~ /&\#(819[6789]|820[01245]);/ig) {
$matchPlace = pos($myLine);
$finalIrregularSpaceOutputLog = ($finalIrregularSpaceOutputLog . 'Caution! IrregularSpaceCharactorRefernce at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $matchPlace . "\n")
}
#キャラクタごとの処理へ
my @eachchara = split(//,$myLine);
our $CharaNumCount = 1;
foreach $mychara(@eachchara){
&eachCharaProceed($myChara);
$CharaNumCount++;
}
}
#各xhtmlファイル内各行内各キャラクタのチェック
sub eachCharaProceed {
my $myChara = $_[0];
###サロゲートペア文字のチェック###
#サロゲートペア文字の場所をチェック、ログに追記
if ($mychara =~ /[\x{20000}-\x{2FFFF}]/){
$finalSarrogatePairOutputLog = ($finalSarrogatePairOutputLog . 'Caution! SarrogatePairCharacters at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $CharaNumCount . "\n")
}
###IVS文字のチェック###
#Unicode IVS文字の場所をチェック、ログに追記
if ($mychara =~ /[\x{E0000}-\x{EFFFF}]/){
$finalIVSOutputLog = ($finalIVSOutputLog . 'Caution! UnicodeIVSCharacters at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $CharaNumCount . "\n")
}
###特殊スペース文字のチェック###
#4分スペースなどの特殊スペース文字が含まれているかどうかのチェック
if ($mychara =~ /[\x{2004}-\x{200A}\x{200C}-\x{200D}]/){
$finalIrregularSpaceOutputLog = ($finalIrregularSpaceOutputLog . 'Caution! IrregularSpaceCharactors at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $CharaNumCount . "\n")
}
###濁点半濁点のチェック###
#HFS+の正規化で分解された濁点半濁点が含まれているかどうかのチェック
if ($mychara =~ /[\x{3099}\x{309A}]/){
$finalVoicedSoundmarkOutputLog = ($finalVoicedSoundmarkOutputLog . 'Caution! VoicedSoundmarkCharactors at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $CharaNumCount . "\n")
}
}
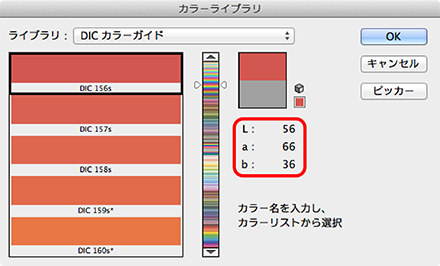 Photoshopのカラーピッカーで「カラーライブラリ」を選び、指定されたDICやPANTONEなどの特色のLab変換値を調べてメモします。
Photoshopのカラーピッカーで「カラーライブラリ」を選び、指定されたDICやPANTONEなどの特色のLab変換値を調べてメモします。 Photoshopのドロップダウンメニュー「編集」から「カラー設定」を選び、「作業用スペース」の「CMYK」で「カスタムCMYK」を選んで「カスタムCMYK」ダイアログボックスを表示させます。
Photoshopのドロップダウンメニュー「編集」から「カラー設定」を選び、「作業用スペース」の「CMYK」で「カスタムCMYK」を選んで「カスタムCMYK」ダイアログボックスを表示させます。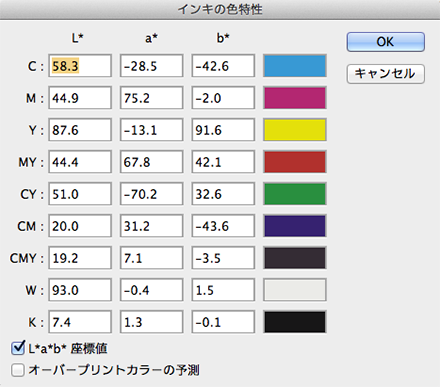 メニュー内の「インキの色特性」ドロップダウンメニューで「カスタム」を選び、「インキの色特性」ダイアログボックスを表示させます。
メニュー内の「インキの色特性」ドロップダウンメニューで「カスタム」を選び、「インキの色特性」ダイアログボックスを表示させます。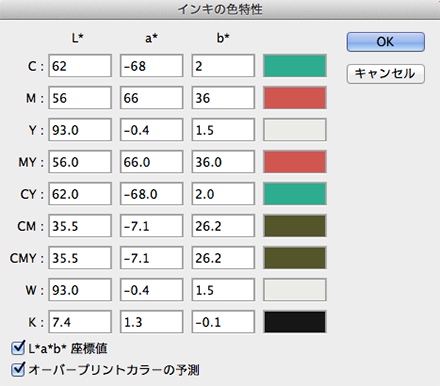 ダイアログボックス下部の「L*a*b座標値」「オーバープリントカラーの予測」のチェックボックスにチェックを入れ、さきほどメモした特色のLab変換値をC/Mの差し替えるカラーの入力欄に入力していきます。使われていないカラーの部分(Y版など)には、ボックス下部にある「W」(ホワイト)の値を入れておきます。「MY」「CY」などの掛け合わせ値は自動で入るので、入力の必要はありません。
ダイアログボックス下部の「L*a*b座標値」「オーバープリントカラーの予測」のチェックボックスにチェックを入れ、さきほどメモした特色のLab変換値をC/Mの差し替えるカラーの入力欄に入力していきます。使われていないカラーの部分(Y版など)には、ボックス下部にある「W」(ホワイト)の値を入れておきます。「MY」「CY」などの掛け合わせ値は自動で入るので、入力の必要はありません。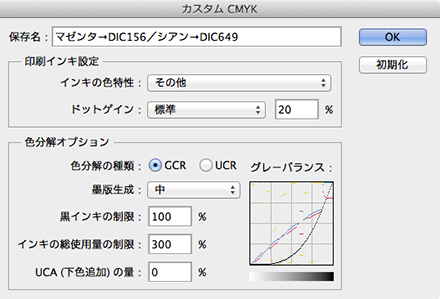 カスタムカラー保存名に「シアン→DIC-○○○差し替え」などとわかりやすい名前を付けてボックスを閉じ、カラー設定ダイアログボックスの「作業用スペース」の「CMYK」のドロップダウンメニューから「CMYKプロファイルとして保存」を選んで、iccプロファイルとして保存します。
カスタムカラー保存名に「シアン→DIC-○○○差し替え」などとわかりやすい名前を付けてボックスを閉じ、カラー設定ダイアログボックスの「作業用スペース」の「CMYK」のドロップダウンメニューから「CMYKプロファイルとして保存」を選んで、iccプロファイルとして保存します。 あとはこの状態のまま画像を開くだけで、特色が差し替わった状態で画像が展開されます。注意点として(当たり前ですが)、開く元の画像はCMYKカラーモデルである必要はあります。
あとはこの状態のまま画像を開くだけで、特色が差し替わった状態で画像が展開されます。注意点として(当たり前ですが)、開く元の画像はCMYKカラーモデルである必要はあります。