EpubCheckでID名がエラーになる問題
2016/08/03先日、弊社で作ったEPUBファイルが電子取次さんのチェックに引っかかって修正で戻ってきたという件がありました。EpubCheck※1のエラーとのことなのですが、弊社でのチェッカーのログはエラーになっていない。どうもEpubCheck3.0.1ではエラーとなっていたものがEpubCheck4.0.1でエラーにならなくなり、チェックに引っかからなかったということのようです。ちょっと困った事態なので突っ込んで調べてみました。
XHTMLのID名のエラー
エラー内容は「value of attribute "id" is invalid; must be an XML name without colons」とのことだったので、まずは該当箇所を見てみます。ID名が「id="toc-001*"」のような形となっており、なるほどこれはエラーになるわけだと一旦は思いました。XMLではID名に「*」の記号を使うことを許容していないからです※2。ということでまずはEpubCheckの各バージョンでこの状態のEPUBでエラーになるかを見てみます。
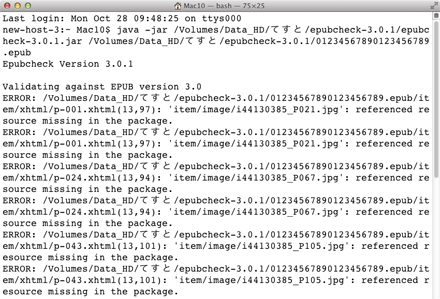
EpubCheck3.0.1だと
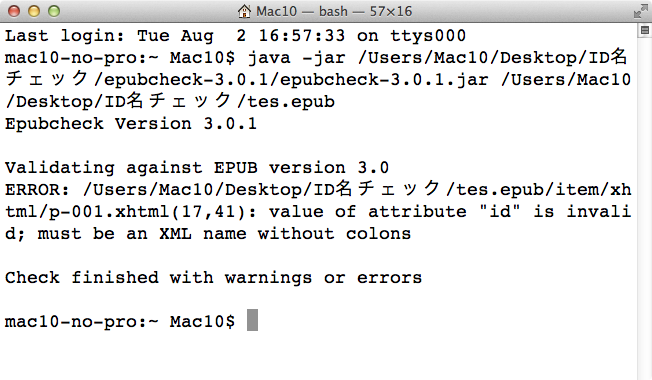
なるほどエラーとなるようです。
EpubCheck4.0.1だと

エラーになりません。なるほど。
では、ちょっとID名を変えて見てみます。「id="toc-あ001"」と、ひらがなの「あ」を入れてみました。この状態でEpubCheckをかけますと
EpubCheck3.0.1で
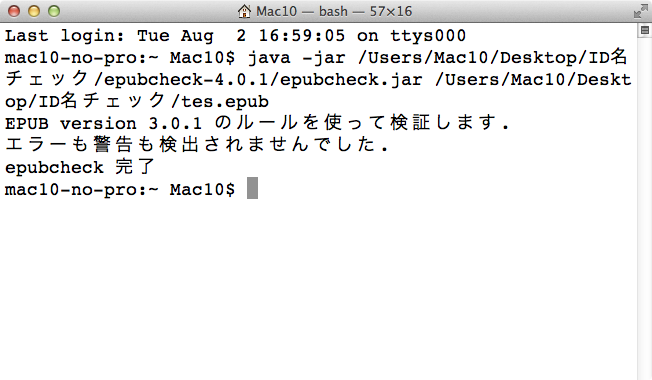
おや、エラーになりませんね。
同じくEpubCheck4.0.1だと
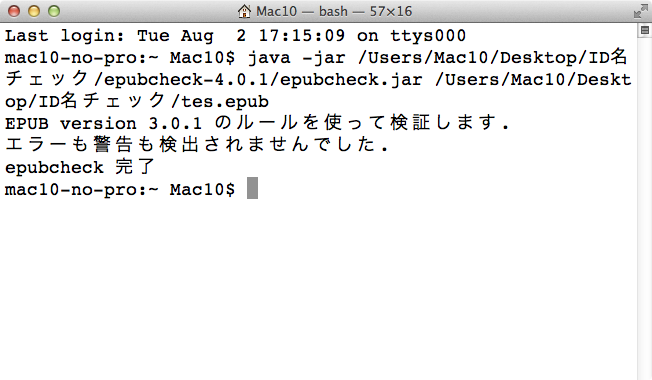
こちらもエラーにならないようです。
HTML5ではID名に何を使ってもよい
困った話だなと思ったのですが、さらに調べるとどうもHTML5では途中にスペースが入らない限りID名に何を使ってもよいとの話もあるようで※3、これに従うと挙動としては実はEpubCheck3.0.1でエラーになるのが間違いだったということになるのでしょうか。
ただ、EPUB3を内部的にXMLなどに変換して表示しているビューアも存在しますので、XMLのID名使用可能文字の制限に従っておくのが無難なのは間違いないと思います。ということでどうやらこの件ではEpubCheckを当てにできませんので、独自にPerlでチェッカーを作ってみました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 |
use utf8; #モジュールをインポート use Encode qw/encode decode/; use File::Basename qw/basename dirname/; use Archive::Zip; use Archive::Extract; use File::Path; #引数1で指定したepubファイルを取得 $epubFilePath = $ARGV[0]; $epubFilePath = decode('UTF-8', $epubFilePath); my $epubFileName = basename $epubFilePath; ###################チェック用一時epubファイルのパスを取得################### my $epubpackage = Archive::Zip->new(); die unless $epubpackage->read($epubFilePath) == Archive::Zip::AZ_OK; #パスリスト変数の定義 my @xhtmlfilePaths; my @files = $epubpackage->members(); #EPUB内各XHTMLファイルへのパスを取得 foreach my $file (@files) { push(@xhtmlfilePaths,$file->fileName) if ($file->fileName =~ /^(.*?)\.xhtml$/); } ###################チェック用一時ファイル解凍処理################### my $uniqueFolderPath = '/tmp/' . $epubFileName; #同一フォルダが存在したら連番をつける処理 my $mynum = 1; if (-d $uniqueFolderPath){ while (-d $uniqueFolderPath){ $uniqueFolderPath = ('/tmp/' . $epubFileName . '_' . $mynum); $mynum++; } } #解凍実行 my $epubArchive = Archive::Extract->new(archive => $epubFilePath,type => 'zip') or die; $epubArchive->extract(to => $uniqueFolderPath); ###################チェック処理################### #ログ出力用変数定義 our $finalXmlIdnameOutputLog = ""; #各xhtmlファイルを展開 foreach $myXhtmlfilePath (@xhtmlfilePaths){ &eachFileProceed($myXhtmlfilePath); } ###################ログにタイトル部分を合成################### if ($finalXmlIdnameOutputLog eq ""){ $finalXmlIdnameOutputLog = '##Xml Idname Check Result : ' . "\r\n" . 'OK! Not Any Irregular Xml IdName in EPUB File!'; } else { $finalXmlIdnameOutputLog = '##Xml Idname Check Result : ' . "\r\n" . $finalXmlIdnameOutputLog; } ###################チェック用一時ファイルの削除################### rmtree($uniqueFolderPath); ###################ログ出力################### my $logOutputPath = (dirname $epubFilePath) . '/EpubIdNameCheck.log'; $logOutputPath = encode('UTF-8', $logOutputPath); open(OUT,">> $logOutputPath"); #チェックしたepubファイル名を出力 my $finalFilename = '####Checked FileName : ' . "\r\n" . $epubFileName; $finalFilename = encode('UTF-8', $finalFilename); print OUT $finalFilename . "\r\n\r\n"; #XMLのID名のチェック結果を出力 $finalXmlIdnameOutputLog = encode('UTF-8', $finalXmlIdnameOutputLog); print OUT $finalXmlIdnameOutputLog . "\r\n\r\n"; close (OUT); exit; ###################Sub################### #各xhtmlファイルのチェック sub eachFileProceed { my $myXhtmlfilePath = $_[0]; #各xhtmlファイル名を取得 our $xhtmlFileName = basename $myXhtmlfilePath; my $eachFilePath = ($uniqueFolderPath . "/" . $myXhtmlfilePath); open(IN,"$eachFilePath"); #改行コードの統一処理 @myCHECKFILEtxts = <IN>; $myCHECKFILEtxts = join("",@myCHECKFILEtxts); $myCHECKFILEtxts =~ s@\x0D\x0A@\x0D@g; $myCHECKFILEtxts =~ s@\x0A@\x0D@g; $myCHECKFILEtxts = decode('UTF-8', $myCHECKFILEtxts); @eachLine = split("\x0D",$myCHECKFILEtxts); close (IN); our $lineNumCount = 1; #各ファイル内各行のチェック foreach $myLine (@eachLine){ &eachLineProceed($myLine); $lineNumCount++; } } #XMLのID名のチェック sub eachLineProceed { my $myLine = $_[0]; while($myLine =~ /id *= *\"([^\"]*?)\"/ig) { unless ($1 =~ /^[0-9a-zA-Z\-\_\.:]+?$/){ $matchPlace = pos($myLine); $finalXmlIdnameOutputLog = ($finalXmlIdnameOutputLog . 'Caution! IrregularXmlIdName at ' . ' ' . 'FileName:' . $xhtmlFileName . ' ' . 'Line:' . $lineNumCount . ' ' . 'Character:' . $matchPlace . "\n") } } } |
こんな感じでしょうか。一応これでチェックは可能となりました。ターミナルで引数にEPUBファイルを指定してやることでログファイルを出力します。環境によってはArchive::Extractモジュールのインストールは必要かもしれません。
◇
EpubCheckはIDPFが配布している公式なEPUBの構造チェッカーですので、まずはこれを通るデータであることが市場流通させられるEPUBの最低条件であることは言うまでもありませんが、各パラメータチェックの細かな部分を見ていくと、必ずしもEpubCheckだけで十分というわけでもないようです。現場サイドでの対応も必要といったところでしょうか。
*1 IDPFの提供している公式なEPUBデータチェック用バリデータ。これでエラーとならないことが市場に流通させられるEPUBの最低条件。
*2 半角の英数字および「.」「:」「_」「-」のみ使用できる
*3 参考:https://www.marguerite.jp/Nihongo/WWW/RefHTML/Attrs/id.html
追記:XML関係の有識者の方にコメントいただきまして、どうやら規格としてはHTML5およびそれを内包しているEPUB3ではID名にはどんな文字を使ってもよい、ということで確定のようです。ただ、実際には古いXML規格で回っているシステムは多数あるかと思いますので、ID名にひらがなや漢字、旧規格で認可されていた以外の記号類を混ぜるようなことはしない方が無難だろうとは思います。規格と実装はまた別です。
(2016.8.3)